
Metode pengujian pengaruh perlakuan tetap pada reancangan acak lengkap dapat juga dilakukan dengan uji Bel Doksum, yaitu uji Bell- Doksum untuk beberapa contoh saling bebas atau sering juga dinyatakan sebagai uji Bell-Doksum untuk k contoh saling bebas. Metode pengujian uji Bell-Doksum ini juga menggunakan prinsip pemeringkatan pada data pengamatan yang asli. Akan tetapi dalam proses perhitunganstatistik uji digunakan bantuan nilai deviasi normal baku. Seperti diketahui bahwa dengan menggunakan deviasi normal baku, dapat diperoleh distribusi pasti dari statistik uji. Dalam pengujian ini digunakan juga hubungan antara distribusi normal baku dan distribusi kai-kuadrat. Misalkan, data terdiri dari k contoh acak yang saling bebas dengan ukuran dapat berbeda. Misalkan juga, j j n j j X1 , X2 ,…X merupakan variabel-variabel acak contoh ke- j yang berukuran nj . Jika N merupakan total keseluruhan ukuran contoh, maka berikan peringkat semua pengamatan pada setiap contoh dengan peringkat dari 1 sampai N seperti pada pemeringkatan Kruskal-Wallis. Peringkat pengamatan Xij dilambangkan dengan ( ) R Xij . Ambil N bilangan dari deviasi normal baku dapat dilakukan dengan pembangkitan atau melihat tabel. Nilai deviasi normal baku ini juga diperingkatkan dari 1 sampai N . Gantikan data pengamatan dengan nilai deviasi normal baku yang memiliki peringkat yang sama. Jika data pengamatan ada yang kembar, maka peringk
Uji Kruskal-Wallis (skripsi dan tesis)
Uji Kruskal-Wallis merupakan perluasan dari uji Mann-Witney dengan contoh independen lebih dari dua. Misal, diketahui Xij adalah pengamatan ulangan ke-i contoh ke- j , k banyaknya contoh acak yang diamati, dengan i = 1,2..,r dan j = 1,2,…, k . Kemudian N adalah banyaknya keseluruhan pengamatan, merupakan penjumlahan dari banyaknya pengamatan masing-masing contoh nj , atau dapat dirumuskan menjadi: ∑= = k j j N n 1 (18) Peringkatkan semua pengamatan untuk seluruh contoh dari data terkecil sampai terbesar, sehingga peringkat data terkecil adalah 1 dan N adalah peringkat data terbesar. Peringkat masing-masing pengamatan dilambangkan dengan ( ) R Xij . Perlu diperhatikan bahwa dalam pemeringkatan, data yang sama atau kembar peringkatnya dirata-ratakan. Rata-rata peringkat ini merupakan peringkat untuk masing-masing pengamatan yang kembar. Keadaan ini yang membedakan uji Kruskall-Wallis terhadap uji Median sebelumnya. Uji Kruskall-Wallis mempertimbangkan pengamatan yang kembar, sedangkan uji Median tidak mempermhatikan informasi tersebut. Setelah data diperingkatkan, kemudian dihitung jumlah peringkat keseluruhan pengamatan pada masing-masing contoh. Jumlah peringkat keseluruhan pengamatan pada contoh ke- j dilambangkan dengan Rj , perhitungannya menggunakan ∑ ( ) = = k j Rj R Xij 1 (19) Kemudian hitung statistik uji Kruskal-Wallis dengan rumus (20) atau (21).
Conover (1971) menyatakan bahwa asumsi-asumsi yang diperlukan untuk melakukan pengujian dengan menggunakan uji Kruskal-Wallis adalah: 1. Semua contoh merupakan contoh acak dari populasinya. 2. Sebagai tambahan dari independensi dalam tiap contoh, juga ada independensi antar contoh. 3. Semua peubah acak Xij kontinu (sejumlah nilai kembar masih diperbolehkan). 4. Skala pengukurannya minimal skala ordinal. 5. Fungsi sebaran k populasi identik atau beberapa populasi cenderung memiliki nilai yang lebih besar dari populasi lainnya. Sedangkan, hipotesis uji Kruskal-Wallis dapat dinyatakan dengan : H0 Semua fungsi sebaran k populasi identik : H1 Sedikitnya ada satu populasi cendrung memiliki nilai yang lebih besar dari populasi lainnya. Uji Kruskal-Wallis sensitif terhadap perbedaan diantara rata-rata k populasinya, sehingga hipotesis alternatifnya dapat juga ditulis menjadi :
H1 k populasi tidak memiliki rata-rata yang sama Kajian Uji Nonparametrik Pengaruh Perlakuan Tetap pada RAL
Distribusi pasti dari H dapat ditentukan, tetapi untuk contoh dan pengulangan yang sedikit karena perhitungannya akan menjadi rumit untuk yang lebih besar. Kruskal-Wallis mengusulkan untuk menggunakan tabel Kruskal-Wallis untuk ukuran contoh kurang dari atau sama dengan lima dan dan banyaknya contoh sama dengan tiga. Jika tidak demikain, maka digunakan distribusi Kai-Kuadrat sebagai pendekatan. Adapun aturan pengambilan keputusan pengujian dengan menggunakan statistik uji Kruskal-Wallis adalah 1. Jika dalam pengujian digunakan k = 3 dan n j k j ≤ 5, =1,2,…, , maka daerah kritis pasti berukuran α dapat diperoleh dari tabel Kruskal-Wallis pada lampiran. Jika nilai H lebih besar dari H pada pada tabel Kruskal-Wallis yang bersesuaian, maka tolak hipotesis nol pada taraf pengujian tertentu. 2. Untuk k > 3 dan n j k j > 5, =1,2,…, , digunakan pendekatan dengan distribusi kai-kuadrat dengan derajat bebas k −1. Jika nilai H lebih besar atau sama dengan kai-kuadrat dengan derajat bebas k −1, maka tolak hipotesis nol pada taraf nyata α tertentu.
Uji Median (skripsi dan tesis)
Untuk melakukan pengujian dengan uji Median, diperlukan beberapa asumsi. Asumsi-asumsi tersebut adalah sebagai berikut (Conover,1971): 1. Setiap contoh adalah contoh acak. 2. Contoh-contoh acak tersebut saling bebas. 3. Skala pengukurannya minimal skala ordinal. 4. Jika setiap populasi memiliki median yang sama, semua populasi memiliki peluang yang sama p dari sebuah pengamatan lebih besar dari median keseluruhan yang sama pula. Hipotesis yang diuji pada uji Median adalah apakah semua contoh yang diambil berasal dari populasi-populasi yang memiliki median-median yang sama.. Hipotesis dapat dituliskan menjadi: H0 H1 : : Semua k populasi memiliki median yang sama Minimal ada satu median populasi yang berbeda
Uji Nonparametrik (skripsi dan tesis)
Uji nonparametrik perlakuan tetap menggunakan data tidak normal. Namun, data yang diproses dalam pengujian atau yang dihitung menggunakan masing-masing statistik ujinya bukan data asli hasil pengamatan, akan tetapi merupakan data ordinal. Data ordinal ini merupakan data baru yang diperoleh dari pemberian pringkat pada data pengamatan asli. Uji nonparametrik perlakuan tetap ini semuanya menggunakan distribusi kaikuadrat sebagai pendekatan, kecuali untuk uji Bell-Doksum. Pada uji Bell-Doksum distribusi kai-kuadrat bukan distribusi pendekatan tetapi merupakan distribusi pasti uji tersebut. Distribusi kai-kuadrat digunakan sebagai pendekatan untuk contoh besar karena kesulitan memperoleh distribusi pasti masing-masing uji. Distribusi kai-kuadrat yang digunakan dalam pembahasan ini menggunakan parameter yang sama yaitu derajat bebasnya k −1. Oleh karenanya, pemahaman mengenai distribusi kai-kuadrat merupakan hal mendasar yang perlu dikenal sebelum melakukan pengujian dengan menggunakan uji-uji nonparametrik ini
Uji Pengaruh Perlakuan Perlakuan Tetap pada RAL (skripsi dan tesis)
Model RAL merupakan model rancangan percobanan yang sederhana. Total variasi pada RAL dibagi menjadi dua, yaitu variasi perlakuan dan variasi galat. Atau dapat dituliskan menjadi Total variasi = variasi perlakuan + variasi galat (1) Dapat juga dituliskan dengan model linier menjadi Yij j ij = μ +τ + ε untuk n j i = 1,2,…, dan j = 1,2,…, k (2) dengan asumsi ( ) 2 ε ij ~ NID 0,σ dan ∑= = k j n j j 1 τ 0 . Banyaknya k perlakuan yang digunakan pada RAL didefinisikan sebagai sebuah himpunan dari k perlakuan populasi yang memiliki rata-rata μ μ μ k , , , 1 2 ” sering disebut rata-rata perlakuan. Dimana rata-rata inilah yang akan diuji pada rancangan acak pengaruh tetap. Apakah semua rata-rata perlakuan tersebut semuanya sama atau tidak. Uji pengaruh perlakuan tetap tetap pada RAL yaitu menguji serentak kesamaan rata-rata perlakuan atau menguji pengaruh perlakuan sama dengan nol. Hipotesis nol ditulis: H0 : μ1 = μ 2 = ” = μ k atau H0 : Semua rata-rata perlakuan sama atau H0 : 0 τ j = , untuk setiap j Jika hipotesis nol diterima, maka rata-rata perlakuan masing-masing populasi sama. Ini mengindikasikan bahwa pengaruh perlakuan tetap pada masing-masing populasi. Pengujian pengaruh perlakuan tetap pada RAL dapat dilakukan dengan metode parametrik maupun metode nonparametrik. Untuk metode parametrik dapat digunakan Analisis Varian (ANAVA) atau uji F , sedangkan untuk uji nonparametrik dapat digunakan uji Median, uji Kruskal-Wallis, dan uji Bell-Doksum.
Uji Kolmogorov-Smirnov Dua Sampel (skripsi dan tesis)
Fungsi Pengujian : Pengujian Satu Sisi adalah untuk menguji perbedaan nilai tengah (median), sedangkan pengujian Dua Sisi untuk menguji berbagai jenis/sembarang perbedaan {(nilai tengah (median), kemencengan (skewness), pemencaran (dispersi)} dua buah populasi yang tidak berpasangan. Persyaratan Data : Data setidak-tidaknya memiliki skala ordinal.
Prosedur Pengujian :
1. Tentukan sebaran frekuensi kumulatif Sn1(x) dan Sn2(x) dalam interval-interval. Jika memungkinkan interval dibuat sebanyak mungkin.
2. Susun skor hasil pengamatan dalam sebaran frekuensi kumulatif Sn1(x) dan Sn2(x).
3. Untuk tiap interval, hitung selisih Sn1(x) dan Sn2(x).
4. Hitung harga D maksimum dengan memakai rumus (5.7).
5. Bila n1 = n2 = N dan jika N ≤ 40, gunakan Tabel L (Siegel, 1997). Tentukan harga p untuk harga KD atau pembilang D maksimum bagi pengujian dua sisi atau satu sisi. Jika KD ≥ KDTabel L, maka tolak Ho.
6. Seandainya n1 dan n2 > 40 dan perlu dilakukan Uji Dua Sisi (n1 dan n2 tidak harus berjumlah sama), gunakan rumus yang ada pada Tabel M (Siegel, 1997) untuk menghitung harga D bagi pengujian dua sisi gunakan rumus (5.8). Jika D ≥ DTabelM, tolak Ho.
7. Seandainya n1 dan n2 > 40 dan perlu dilakukan Uji Satu Sisi, hitung harga χ 2 berdasarkan harga D maksimum, dengan memakai rumus (5.9). Selanjutnya gunakan Tabel C (Siegel, 1997) untuk harga χ 2 pada db = 2. Jika p yang diamati ≤ α , maka tolak Ho.
Uji U Mann-Whitney (skripsi dan tesis)
Fungsi Pengujian : Untuk menguji perbedaan nilai tengah (median) skor dua buah populasi berdasarkan dua sampel yang tidak berpasangan. Persyaratan Data : Data paling tidak memiliki sakala ordinal.
Prosedur Pengujian :
1. Tentukan jumlah n1 dan n2. Dalam pengertian ini n1 adalah jumlah sampel yang berukur lebih kecil dari n2.
2. Gabungkan n1 dan n2, berikan rangking kepada skor-skornya dengan memperhatikan tanda + dan -. Skor disusun dari mulai 1 – k (=n1+n2). Untuk rangking kembar cari ratarata rangkingnya.
3. Untuk 3 ≤ n1 dan n2 ≤ 8. Perhatikan frekuensi skor n1 dan n2 dalam urutan skor gabungan. Hitung jumlah frekuensi skor n1 yang mendahului n2 atau sebaliknya. Jumlah seluruh frekuensi skor yang mendahului = U. Selanjutnya gunakan Tabel J (Siegel, 1997). Tentukan probabilitas (p) yang dikaitkan dengan terjadinya suatu harga sebesar U menurut n1 dan n2. Seandainya harga U tidak ditemukan dalam Tabel J, buat modifikasi dengan memakai rumus (5.4). Harga-harga p tersebut dipakai untuk pengujian satu sisi, sedangkan untuk melakukan pengujian dua sisi harga p = 2 x pTabel . Jika p ≤ α, maka tolak Ho.
4. Untuk 9 ≤ n2 ≤ 20. Perhatikan frekuensi skor n1 dan n2 dalam urutan skor gabungan. Hitung jumlah frekuensi skor n1 yang mendahului n2 atau sebaliknya. Jumlah seluruh frekuensi skor yang mendahului = U. Selanjutnya gunakan Tabel K (Siegel, 1997). Tentukan probabilitas (p) yang dikaitkan dengan terjadinya suatu harga sebesar U menurut n1 dan n2. Seandainya harga U tidak ditemukan dalam Tabel K, buat modifikasi dengan memakai rumus (5.4). Harga-harga p tersebut dipakai untuk pengujian satu sisi, sedangkan untuk melakukan pengujian dua sisi harga p = 2 x pTabel . Jika p ≤ α, maka tolak Ho.
5. Untuk n2 > 21. Perhatikan frekuensi skor n1 dan n2 dalam urutan skor gabungan. Hitung jumlah frekuensi skor n1 yang mendahului n2. Jumlah seluruh frekuensi skor n1 yang mendahului n2 = U. Hitung Harga z dengan memakai rumus (5.5). Selanjutnya gunakan Tabel A (Siegel, 1997). Tentukan probabilitas (p) yang dikaitkan dengan terjadinya suatu harga z. Hargaharga p tersebut dipakai untuk pengujian satu sisi, sedangkan untuk melakukan pengujian dua sisi harga p = 2 x pTabel . Jika p ≤ α, maka tolak Ho.
Uji Chi Kuadrat (χ 2 ) Dua Sampel Tak Berpasangan (skripsi dan tesis)
Fungsi Pengujian : Hampir sama dengan Uji Fisher, yaitu untuk menguji perbedaan proporsi dua buah populasi berdasarkan proporsi dua sampel yang tidak berpasangan. Kelebihan Uji χ 2 bisa dipakai untuk dua atau lebih kategori. Uji χ 2 sebaiknya digunakan jika n > 40. Untuk 20 < n < 40 dengan frekuensi kategori-kategorinya (Oij ≥ 5) bisa digunakan Uji χ 2 , namun jika ada salah satu frekuensi < 5 Uji χ 2 tidak boleh digunakan. Untuk n < 20 pilihlah Uji Fisher.
Persyaratan Data : Dapat digunakan untuk data berskala nominal dengan dua atau lebih dari dua kategori. Prosedur Pengujian :
1. Buat Tabel Silang (k x r), k adalah kolom = 2 dan r adalah baris ≥ 2. Kolom dipakai untuk dua pasangan sampel yang tidak berpasangan, sedangkan baris disediakan untuk berbagai kategori.
2. Masukan frekuensi-frekuensi hasil pengamatan (Oij) ke dalam Tabel.
3. Hitung dan masukan ke dalam Tabel, frekuensi-frekuensi yang diharapkan (Eij) yang dihitung dengan cara mengalikan jumlah baris dan jumlah kolom pada posisi Eij kemudian membaginya dengan total frekuensi (N).
4. Hitung harga χ 2 memakai rumus (5.2). 5. Untuk k=2 dan r=2, hitung dengan rumus (5.3). Pengertian dari notasi yang ada dalam rumus ini. . Gunakan Tabel C (Siegel, 1997). Tentukan probabilitas (p) yang dikaitkan dengan terjadinya suatu harga sebesar χ 2 pada db = (r-1)(k-1). Harga-harga p tersebut dipakai untuk pengujian dua sisi, sedangkan untuk melakukan pengujian satu sisi harga p = ½ pTabel
Uji Fisher (skripsi dan tesis)
Fungsi Pengujian : Untuk menguji perbedaan proporsi dua buah populasi yang hanya memiliki dua kategori berdasarkan proporsi dua sampel tidak berpasangan. Jumlah n untuk tiap kelompok sampel tidak harus sama.
Persyaratan Data : Dapat digunakan untuk data berskala nominal dengan dua kategori
Prosedur Pengujian :
1. Buat Tabel Silang
Baris adalah kelompok sampel, dan kolom – dan + untuk menunjukkan kategori yang bersifat muttualy exclusive.
2. Masukan frekuensi-frekuensi hasil pengamatan ke dalam baris dan kolom yang tepat.
3. Hitung jumlah frekuensi ke arah baris dan kolom, N adalah jumlah keseluruhan frekuensi pengamatan.
4. Untuk uji signifikansi ( 6 ≤ n ≤ 30), gunakan Tabel I (Siegel, 1997) yang merupakan pengujian satu sisi, sedangkan untuk pengujian dua sisi harga p = 2 x p Untuk uji signifikansi yang lebih cermat (eksak), gunakan rumus yang menghasilkan harga p uji satu sisi, sedangkan untuk pengujian dua sisi harga p dikalikan 2. Praktis digunakan jika n tidak terlampau besar. Meskipun demikian bisa dipakai untuk n > 30, tetapi kemungkinan di daerah penolakan tidak terlampau banyak
6. Jika p yang dihasilkan dari perhitungan ternyata ≤ α, maka tolak Ho
Uji Tanda Wilcoxon (skripsi dan tesis)
Fungsi Pengujian : Untuk menguji perbedaan median dua populasi berdasarkan median dua sampel berpasangan. Uji ini selain mempertimbangkan arah perbedaan, juga mempertimbangkan besar relatif perbedaannya. Dengan demikian bisa dikatakan bahwa Uji Tanda Wilcoxon memiliki kualitas yang lebih baik dibandingkan dengan Uji Tanda yang dibahas sebelumnya. Persyaratan Data : Data paling tidak berskala ordinal.
Prosedur Pengujian :
1. Urutkan nilai jenjang/skor setiap pasangan dari anggota kelompok sampel pertama dan kedua.
2. Hitung nilai beda (di) untuk setiap pasangan anggota kelompok sampel pertama dan kedua.
3. Buat ranking untuk setiap di tanpa memperhatikan tandanya (positif atau negatif). Rangking ke-1 diberikan terhadap harga mutlak di terkecil. Jika ada ranking kembar buat rata-rata rankingnya
. 4. Pada ranking di , cantumkan tanda + dan -, sesuai dengan tanda + dan – pada nilai beda (di).
5. Pisahkan ranking di yang memiliki tanda + atau – paling sedikit.
6. Tentukan nilai T, dengan cara menjumlahkan nilai rangking di yang memiliki tanda + atau – paling sedikit tanpa memperhatikan tandanya (nilai harga mutlak rangking di).
7. Tentukan pula nilai N, dengan cara menghitung frekuensi di yang memiliki tanda + dan -, sedangkan frekuensi di yang memiliki tanda 0 jangan dimasukan ke dalam hitungan.
8. Jika N ≤ 25, lihat Tabel G (Siegel, 1997) yang menyajikan kemungkinan satu sisi/one tailed dan dua sisi/two tailed untuk harga T dari pengamatan di bawah Ho. Jika harga T dari pengamatan ≤ TTabel , maka tolak Ho untuk tingkat signifikansi tertentu.
9. Jika N > 25 , gunakan rumus (4.3). Sedangkan tabel yang digunakan adalah Tabel A (Siegel, 1997) yang menyajikan kemungkinan satu sisi/one tailed untuk kemunculan harga z pengamatan di bawah Ho. Uji satu sisi digunakan apabila telah memiliki perkiraan skor kelompok sampel tertentu akan lebih besar atau lebih kecil dari skor kelompok sampel yang lainnya. Jika belum memiliki perkiraan, harga p dalam Tabel A dikalikan dua (harga p = p-Tabel x 2). Jika p diasosiasikan dengan harga z yang diamati ternyata ≤ α, maka tolak Ho.
Uji Tanda (skripsi dan tesis)
Fungsi Pengujian : Untuk menguji perbedaan/perubahan ranking (median selisih skor/ranking) dua buah populasi berdasarkan ranking (median selisih skor/ranking) dua sampel berpasangan. Persyaratan Data : Data paling tidak berskala ordinal.
Prosedur Pengujian : 1. Urutkan nilai jenjang setiap pasangan dari anggota kelompok sampel pertama dan kedua. 2. Kepada masing-masing pasangan berikan tanda + (plus) dan – (minus) sebagai kode/tanda selisih jenjang dari setiap pasangan. 3. Tentukan harga N, yaitu jumlah semua pasangan yang memiliki tanda + dan -.Tentukan pula nilai x, yaitu jumlah pasangan yang memiliki kesamaan tanda lebih sedikit. 5. Jika N ≤ 25 , lihat Tabel D (Siegel, 1997) yang menyajikan kemungkinan satu sisi/one tailed untuk kemunculan harga x dari pengamatan di bawah Ho. Uji satu sisi digunakan apabila telah memiliki perkiraan ranking kelompok sampel tertentu akan lebih besar atau lebih kecil dari ranking kelompok sampel yang lainnya. Seandainya kita belum mempunyai perkiraan, harga p dalam Tabel D dikalikan dua (harga p = p-Tabel D x 2). 6. Jika N > 25 , gunakan rumus (4.2). Sedangkan tabel yang digunakan adalah Tabel A (Siegel, 1997) yang menyajikan kemungkinan satu sisi/one tailed untuk kemunculan harga z pengamatan di bawah Ho. Uji satu sisi digunakan apabila telah memiliki perkiraan ranking kelompok sampel tertentu akan lebih besar atau lebih kecil dari ranking kelompok sampel yang lainnya. Jika belum memiliki perkiraan, harga p dalam Tabel A dikalikan dua (harga p = p-Tabel A x 2). 7. Jika p diasosiasikan dengan harga x atau z yang diamati ternyata < α , maka tolak Ho.
Uji Chi Kuadrat (χ 2 ) Mc. Nemar (skripsi dan tesis)
Fungsi Pengujian : Untuk menguji perbedaan atau perubahan proporsi dua buah populasi yang hanya memiliki dua kategori berdasarkan proporsi dua sampel berpasangan. Uji ini banyak dipakai untuk mengetahui apakah ada perbedaan atau perubahan proporsi sebelum dan sesudah kelompok sampel tertentu yang hanya memiliki dua kategori diberi perlakuan, dimana anggota kelompok sampel tersebut merupakan kontrol terhadap dirinya sendiri.
Persyaratan Data : Dapat digunakan untuk data berskala nominal dengan dua kategori. Prosedur Pengujian : 1. Buat Tabel Silang 2 x 2, seperti contoh pada Tebel 4.1 di bawah ini. Tanda + dan – dipakai untuk menunjukkan adanya perubahan. Tentukan frekuensi-frekuensi harapan (E) dari sel A dan sel D, E = ½ (A+D). Frekuensi harapan harus ≥ 5. 3. Jika E ≥ 5, hitung harga χ 2 menggunakan rumus (4.1). Tetapi jika E < 5, Uji χ2 Mc. Nemar tidak boleh gunakan, dan untuk penggantinya dapat dipakai Uji Binomial. 4. Gunakan Tabel C (Siegel, 1997). Tentukan probabilitas (p) yang dikaitkan dengan terjadinya suatu harga sebesar χ 2 untuk harga db =1, untuk pengujian dua sisi. 5. Jika p yang diamati ternyata ≤ α , maka tolak Ho.
Uji Kolmogorov-Smirnov Sampel Tunggal (skripsi dan tesis)
Fungsi Pengujian : Untuk menguji perbedaan proporsi populasi, yaitu antara data yang diamati dengan yang telah ditentukan menurut Ho, berdasarkan proporsi data yang berasal dari sampel tunggal. Persyaratan Data : Dipakai untuk data berskala ordinal namun dapat digunakan juga bagi data berskala nominal.
Prosedur Pengujian : 1. Tentukan sebaran frekuensi kumulatif teoritis Fo(x), yaitu sebaran frekuensi kumulatif di bawah Ho. 2. Susun skor hasil pengamatan dalam sebaran frekuensi kumulatif pengamatan Sn(x) yang sesuai dengan Fo(x). 3. Untuk tiap jenjang/rank, hitung selisih harga mutlak Fo(x) – Sn(x). 4. Hitung harga D maksimum dengan memakai rumus (3.3). 5. Gunakan Tabel E (Siegel, 1997). Tentukan harga p untuk harga D maksimum (pengujian dua sisi). 6. Jika p yang diamati ternyata ≤ α , maka tolak Ho
Uji Chi Kuadrat (χ2) Sampel Tunggal (skripsi dan tesis)
Fungsi Pengujian :
Untuk menguji perbedaan proporsi populasi, yaitu antara data yang diamati dengan data yang diharapkan (expected) terjadi menurut Ho, berdasarkan proporsi yang berasal dari sampel tunggal.
Persyaratan Data :
Dapat digunakan untuk data berskala nominal dengan dua atau lebih dari dua kategori.
Prosedur Pengujian :
1. Tentukan n = jumlah semua kasus yang diteliti.
2. Tentukan jumlah frekuensi dari masing-masing kategori (k). Jumlah frekuensi seluruhnya= n.
3. Berdasarkan Ho , tentukan frekuensi yang diharapkan (Ei) dari k. Jika k = 2, frekuensi yang diharapkan minimal 5. Jika k > 2 dan (Ei) < 5 lebih dari 20%, gabungkanlah k yang berdekatan, agar banyaknya (Ei) < 5 dalam k tidak lebih dari 20%.
4. Hitung harga χ
2 dengan menggunakan rumus (3.2).
5. Tentukan derajat bebas, db = k – 1.
6. Gunakan Tabel C (Siegel, 1997), tabel ini untuk pengujian dua sisi. Tentukan probabilitas
(p) yang dikaitkan dengan terjadinya suatu harga sebesar χ
2 untuk harga db yang bersangkutan.
7. Jika p yang diamati ternyata ≤ α , maka tolak H
Uji Binomial (skripsi dan tesis)
Fungsi Pengujian :
Untuk menguji perbedaan proporsi populasi yang hanya memiliki dua buah kategori berdasarkan proporsi sampel tunggal.
Persyaratan Data :
Dapat digunakan untuk data berskala nominal yang hanya memiliki dua kategori.
Prosedur Pengujian :
1. Tentukan n = jumlah semua kasus yang diteliti.
2. Tentukan jumlah frekuensi dari masing-masing kategori.
3. Jika n ≤ 25 dan jika P=Q=½, lihat Tabel D (Siegel, 1997) yang menyajikan kemungkinan satu sisi/one tailed untuk kemunculan harga x yang lebih kecil dari pengamatan di bawahHo. Uji satu sisi digunakan apabila telah memiliki perkiraan frekuensi mana yang lebihkecil. Jika belum memiliki perkiraan, harga p dalam Tabel D dikalikan dua (harga p =pTabel x 2).
4. Jika n > 25 dan P mendekati ½, gunakan rumus (3.1). Sedangkan tabel yang digunakan adalah Tabel A (Siegel, 1997) yang menyajikan kemungkinan satu sisi/one tailed untuk kemunculan harga z pengamatan di bawah Ho. Uji satu sisi digunakan apabila telah memiliki perkiraan frekuensi mana yang lebih kecil. Jika belum memiliki perkiraan,
harga p dalam Tabel A dikalikan dua (harga p = pTabel x 2).
5. Jika p diasosiasikan dengan harga x atau z yang diamati ternyata ≤ α , maka tolak Ho
Hipotesis Statistik (skripsi dan tesis)
Adalah pernyataan mengenai parameter dari populasi yang didasarkan pada statistik dari sampel. Bentuk pernyataannya bisa didasarkan atas kesamaan-kesamaan atau perbedaanperbedaan, ada tidaknya asosiasi maupun hubungan-hubungan antar variabel, juga penaksiran-penaksiran nilai populasi. Dari hipotesis yang dicontohkan di atas, berarti peneliti menduga usaha ternak ayam ras lebih menguntungkan dibandingkan usaha tani padi. Pernyataan yang menyiratkan adanya perbedaan tersebut secara statistik dapat ditulis sebagai berikut : Ho : µa ≤ µp H1 : µa > µp H1 berarti rata-rata keuntungan yang diperoleh peternak ayam ras lebih besar jika dibandingkan dengan petani yang berusaha tani padi. Sedangkan Ho menyatakan, rata-rata keuntungan yang diperoleh peternak ayam ras sama dengan atau lebih kecil dari petani yang melakukan usaha tani padi. Ho dan H1 merupakan pasangan hipotesis statistik yang akan dipakai sebagai titik tolak untuk menduga parameter. Pada uji hipotesis statistik, pengujian diarahkan untuk menduga Ho apakah bisa diterima atau harus ditolak.
Hipotesis Nol (skripsi dan tesis)
Adalah kebalikan atau hipotesis yang menolak pernyataan hipotesis penelitian. Dalam konteks penyangkalan terhadap contoh hipotesis penelitan tadi, pernyataan hipotesis nol bisa menjadi: rata-rata keuntungan dari usaha ternak ayam ras sama dengan atau lebih kecil dari usaha tani padi. Dalam statistika hipotesis yang menyatakan penolakan terhadap hipotesis penelitian diberi lambang Ho
Hipotesis Penelitian (skripsi dan tesis)
Merupakan suatu pernyataan yang dibuat berdasarkan pada fenomena dan teori-teori, yang dirangkaikan secara logis dalam sebuah kerangka pikir. Oleh peneliti, hipotesis penelitian “dianggap” benar dan bisa diterima secara logika. Tetapi karena sesungguhnya teori itu merupakan dalil dari sifat yang “sebenarnya”, maka hipotesis penelitian pun hanya bisa dipandang sebagai dugaan sementara yang masih memerlukan pengujian. Contoh dari hipotesis penelitian adalah: rata-rata keuntungan dari usaha ternak ayam ras lebih besar jika dibandingkan dengan keuntungan usaha tani padi. Dalam statistika hipotesis penelitian diberi lambang H1
Statistika Parametrik dan Nonparametrik (skripsi dan tesis)
Pada perkembangan statistika inferensial, metode-metode penafsiran yang berasal dari generasi awal, menetapkan asumsi-asumsi yang sangat ketat dari karakteristik populasi yang diantara anggota-anggota populasinya diambil sebagai sampel. Di bawah asumsi-asumsi tersebut, diharapkan angka-angka atau statistik dari sampel, betul-betul bisa mencerminkan angka-angka atau parameter dari populasi. Oleh karena itu, dikenal dengan istilah Statistika Parametrik. Asumsi-asumsi tersebut antara lain: data (sampel) harus diambil dari suatu populasi yang berdistribusi normal. Seandainya sampel diambil dari dua atau lebih populasi yang berbeda, maka populasi tersebut harus memiliki varians (δ 2 ) yang sama. Selain itu, statistika parametrik hanya boleh digunakan jika data memiliki nilai dalam bentuk numerik atau angka nyata. Ketatnya asumsi dalam statistika parametrik, secara metodologis sulit dipenuhi oleh peneliti-peneliti dalam bidang ilmu sosial. Sebab dalam kajian sosial, sulit untuk memenuhi asumsi distribusi normal maupun kesamaan varians (δ 2 ), selain itu banyak data yang tidak berbentuk numerik, tetapi hanya berupa skor rangking atau bahkan hanya bersifat nilai kategori. Oleh karenanya, statistika inferensial saat ini banyak berkembang kepada teknikteknik yang tidak berlandaskan pada asumsi-asumsi di atas, yang dikenal sebagai Statistika Nonparametrik.
Menafsirkan Parameter Berdasarkan Statistik (skripsi dan tesis)
Telah diuraikan terdahulu, terdapat metode-metode tertentu yang bisa dipakai untuk menginterpretasikan data dalam kondisi ketidakpastian (uncertainty), yaitu statistika inferensial. Fokus kajian statistika inferensial adalah untuk menafsirkan parameter (populasi) berdasarkan statistik (sampel) melalui pengujian hipotesis. Dalam pengujian hipotesis, titik tolaknya adalah menduga parameter yang dinyatakan oleh pasangan hipotesis statistik, misalnya: Ho; µ1 = µ2 dan H1; µ1 ≠ µ2. Masalah umum yang dihadapi dalam menafsirkan parameter dari populasi yang berdasarkan satistik dari sampel adalah, adanya faktor kesempatan/kebetulan (chance) dalam pengambilan data. Kemudian bisa timbul pertanyaan, apakah hasil pengamatan tentang adanya persamaam atau perbedaan parameter dalam populasi atau antar populasi, juga disebabkan oleh faktor kebetulan dalam pengambilan data? Untuk itu statistika inferensial menyediakan berbagai prosedur yang memungkinkan untuk menguji, apakah adanya persamaan atau perbedaan tadi disebabkan karena faktor kebetulan atau tidak
Statistika Deskriptif dan Inferensial (skripsi dan tesis)
Pada proses pengumpulan data di atas, tentu saja tidak bisa dilakukan secara sembarangan tetapi ada tahapan-tahapan dan cara-cara atau teknik-teknik tertentu sebagai pedomannya yang kita sebut sebagai metode. Metode ini dikenal sebagai statistika. Dalam statistika, ada metode-metode tertentu sebagai pedoman untuk menyajikan data sehingga secara ringkas dapat dengan mudah dipahami. dan sebagainya. Metode penyederhanaan data sehingga mudah dipahami dikenal sebagai statistika deskriptif. Statistika deskriptif pada awalnya merupakan bidang kajian yang sangat penting, walaupun saat ini bukan merupakan bidang kajian pokok dalam statistika. Tujuan utama statistika saat ini adalah menginterpretasikan atau menafsirkan (inference) data, yang dikenal dengan istilah statistika inferensial. Misalnya dengan melihat grafik rata-rata pemilikan lahan berdasarkan status sosial ekonomi petani, melalui angka-angkanya kita bisa melihat bahwa rata-rata pemilikan lahan petani dengan tingkat sosial ekonomi tertentu lebih luas dibandingkan dengan status ekonomi lainnya. Tapi untuk melakukan interpretasi lebih jauh, kita harus menyadari bahwa statistik yang tersaji berasal dari suatu sampel bukannya populasi, sehingga belum tentu menggambarkan kondisi yang sebenarnya, atau dengan kata lain masih berada dalam suatu kondisi ketidakpastian
Statistika, Statistik, dan Parameter (skripsi dan tesis)
Dalam perbincangan sehari-hari kita sering mendengar kata statistik maupun statistika. Namun penggunaan dari dua kata tersebut masih simpang siur. Adakalanya pengertian yang seharusnya statistik ditulis atau disebut dengan istilah statistika, demikian pula sebaliknya pengertian statistika sering ditulis atau disebut dengan istilah statistik. Walaupun penulisannya sangat mirip antara statistik dengan statistika, tetapi memiliki arti yang sangat berlainan. Pengertian statistik (statistic) adalah bilangan yang diperoleh melalui proses perhitungan terhadap sekumpulan data yang berasal dari sampel. Sedangkan pengertian statistika (statistics) adalah konsep dan metode yang bisa digunakan untuk mengumpulkan, menyajikan, dan menginterpretasikan data dari kejadian tertentu untuk mengambil suatu keputusan/kesimpulan dalam suatu kondisi adanya ketidakpastian. Misalnya kita ingin mengetahui rata-rata luas lahan yang dimiliki petani di suatu propinsi. Untuk menghitung seluruh luas lahan pertanian di propinsi tersebut membutuhkan biaya dan waktu yang tidak sedikit, sehingga diputuskan untuk mengambil sampel dari beberapa kabupaten. Dari kabupaten sampel diperoleh data berapa luas lahan dan berapa jumlah petaninya, dengan demikian kita bisa menghitung rata-rata luas lahan yang dimiliki petani. Angka rata-rata luas lahan yang diperoleh disebut statistik. Seandainya data tersebut diperoleh dari seluruh propinsi, angka rata-ratanya tidak bisa disebut statistik, tetapi disebut parameter karena tidak diperoleh dari sampel melainkan diperoleh dari populasi
Teknik Sampling (skripsi dan tesis)
Teknik sampling merupakan teknik pengambilan sampel. Untuk
menentukan sampel yang akan digunakan dalam penelitian, terdapat berbagai
teknik sampling yang digunakan (Sugiyono, 2013). Pada dasarnya teknik
sampling dapat dikelompokkan menjadi dua, yaitu probability sampling dan
nonprobability sampling. Probability sampling meliputi, simple random,
proportionate stratified random, disproportionate stratified random, dan area
random. Sedangkan nonprobability sampling meliputi sampling sistematis, sampling kuota, sampling aksidental/insidental, purposive sampling, sampling
jenuh, dan snowball sampling.
Sampel (skripsi dan tesis)
Sampel adalah bagian dari jumlah dan karakteristik yang dimiliki oleh
populasi tersebut. Bila populasi besar, dan peneliti tidak mungkin mempelajari
semua yang ada pada populasi, misalnya karena keterbatasan dana, tenaga dan
waktu, maka peneliti dapat menggunakan sample yang diambil dari populasi itu.
Apa yang dipelajari dari sample itu, kesimpulannya akan dapat diberlakukan
untuk populasi. Untuk itu sampel yang diambil dari populasi harus betul-betul
representatif (Sugiyono, 2013).
Menurut Yusuf (2014), ciri-ciri sampel yang baik adalah sebagai berikut :
a. Sampel dipilih dengan cara hati-hati, dengan menggunakan cara tertentu
dengan benar.
b. Sampel harus mewakili populasi, sehingga gambaran yang diberikan
mewakili keseluruhan karakteristik yang terdapat pada populasi.
c. Besarnya ukuran sampel hendaklah mempertimbangkan tingkat kesalahan
sampel yang dapat ditoleransi dan tingkat kepercayaan yang dapat diterima
secara statistik.
Populasi (skripsi dan tesis)
Menurut Sugiyono (2013), populasi adalah wilayah generalisasi yang
terdiri atas obyek atau subyek yang mempunyai kualitas dan karakteristik
tertentu yang ditetapkan oleh peneliti untuk dipelajari dan kemudian ditarik
kesimpulannya. Jadi populasi bukan hanya orang, tetapi juga obyek dan bendabenda
alam yang lain. Populasi juga bukan sekedar jumlah yang ada pada
obyek atau subyek yang dipelajari, tetapi meliputi seluruh karakteristik atau
sifat yang dimiliki oleh subyek atau obyek itu.
Yusuf (2014) menyatakan, secara umum dapat dikatakan beberapa
karakteristik populasi, yaitu :
a. Merupakan keseluruhan dari unit analisis sesuai dengan informasi
yang akan diinginkan.
b. Dapat berupa manusia, hewan, tumbuh-tumbuhan, benda atau objek
maupun kejadian yang terdapat dalam suatu area/daerah tertentu
yang telah ditetapkan.
c. Merupakan batas (boundary) yang mempunyai sifat tertentu yang
memungkinkan peneliti menarik kesimpulan dari keadaan itu.
d. Memberikan pedoman kepada apa atau siapa hasil penelitian itu
dapat digeneralisasikan.
Statistik (skripsi dan tesis)
Menurut Sugiyono (2014) dalam arti sempit statistik dapat diartikan
sebagai data, tetapi dalam arti luas statistik dapat diartikan sebagai alat, alat
untuk analisis, dan alat untuk membuat keputusan. Statistik dapat dibedakan
menjadi dua, yaitu :
a. Statistik deskriptif adalah statistik yang digunakan untuk menggambarkan
atau menganalisis suatu statistik hasil penelitian, tetapi tidak digunakan
untuk membuat kesimpulan yang lebih luas.
b. Statistik inferensial adalah statistik yang digunakan untuk menganalisis data
sampel, dan hasilnya akan digeneralisasikan untuk populasi di mana sampel
diambil. Selanjutnya statistik inferensial dapat dibedakan menjadi statistik
parametris dan non parametris. Statistik parametris digunakan untuk
menganalisis data interval atau rasio, yang diambil dari populasi yang
berdistribusi normal. Sedangkan statistik non parametris, digunakan untuk
menganalisis data nominal dan ordinal dari populasi yang bebas distribusi
Uji Beda Rata-Rata Sampel Berpasangan (skripsi dan tesis)
Untuk menguji adanya perbedaan antara dua rata-rata, kita harus memilih apakah menggunakan a one-tailed test atau a two-tailed test. Apabila pengujiannya terkait ada perbedaan atau tidak ada perbedaan maka menggunakan a twotailed test untuk mengukur apakah satu rata-rata berbeda dengan yang lain (lebih tinggi atau lebih rendah) (Levin, 1998). Paired sample t test bertujuan untuk menguji ada tidaknya perbedaan mean untuk dua kelompok yang berpasangan. Subjeknya sama, namun mengalami dua perlakuan atau pengukuran yang berbeda (Nisfiannoor, 2009). Untuk melakukan uji beda rata-rata berpasangan harus memenuhi syarat sebagai berikut: 1. Data sampel merupakan data dependen 2. Sampel diambil secara acak sederhana 3. Salah satu atau kedua syarat berikut terpenuhi: a. Pasangan sampel data berjumlah besar (n>30) b. pasangan sampel berasal dari populasi yang memiliki distribusi yang mendekati normal (Triola, 2015). Dalam melakukan uji beda rata-rata, apabila data tidak berdistribusi normal maka digunakan uji statistik nonparametrik yang dapat menggunakan teknik Wilcoxon signed ranks test (Nisfiannoor, 2009).
Cara yang lebih baik untuk membandingkan prosedur pengujian t-test dan Wilcoxon signed ranks test adalah dengan melihat perkiraan tingkat kesalahan Tipe I dan Tipe II. Jelas bahwa prosedur Wilcoxon signed ranks test melindungi lebih baik terhadap kesalahan Tipe I karena rata-rata tingkat kesalahan Tipe I selalu lebih rendah daripada uji-t. Sementara rata-rata tingkat kesalahan Tipe II menggunakan uji-t lebih rendah daripada yang menggunakan uji Wilcoxon signed ranks test untuk setiap set perbedaan rata-rata (Meek et al., 2007). Saat menguji hipotesis nol, kita sampai pada kesimpulan menolak atau gagal untuk menolaknya. Kesimpulan semacam itu terkadang benar dan terkadang salah (bahkan jika kita menerapkan semua prosedur dengan benar). Terdapat dua jenis kesalahan, yaitu Kesalahan Tipe I dan Tipe II. a. Kesalahan Tipe I: kesalahan menolak hipotesis nol ketika pada kenyataannya benar. b. Kesalahan Tipe II: kesalahan tidak menolak hipotesis nol ketika pada kenyataannya salah (Triola, 2015). Banyak metode analisis statistik diturunkan setelah membuat asumsi tentang distribusi data yang mendasarinya (misalnya, normalitas). Namun, kita juga dapat mempertimbangkan metode nonparametrik untuk menarik kesimpulan statistik di mana tidak ada asumsi yang dibuat tentang populasi atau distribusi yang mendasarinya. Untuk nonparametrik setara dengan uji t parametik satu-sampel dan dua-sampel, Wilcoxon signed ranks test (satu sampel) digunakan untuk menguji hipotesis bahwa perbedaan median antara nilai absolut perbedaan berpasangan positif dan negatif adalah 0 (Harris & Hardin, 2013). Wilcoxon signed ranks test digunakan untuk membandingkan dua kondisi ketika peserta yang sama ikut serta dalam setiap kondisi dan data yang dihasilkan tidak terdistribusi secara normal. Tes ini diterapkan pada sampel berpasangan yang didasarkan pada perbedaan antara skor dalam dua kondisi yang berbeda. Setelah perbedaan-perbedaan ini dihitung, kemudian diberi peringkat tetapi tanda perbedaannya (positif atau negatif) ditetapkan ke peringkat tersebut. Dalam hal menggunakan program SPSS terdapat beberapa hal yang perlu diperhatikan, yaitu: a. Lihat baris berlabel Asymp. Sig. (2- tailed). Jika nilainya kurang dari 0,05 maka kedua kelompok berbeda secara signifikan. b. Lihat peringkat positif dan negatif (dan catatan kaki yang menjelaskan apa artinya) untuk memberi tahu Anda bagaimana perbedaan kelompok (semakin banyak peringkat di arah tertentu memberi tahu Anda arah hasilnya). c. SPSS hanya memberikan nilai signifikansi dua sisi; jika Anda ingin signifikansi satu sisi cukup bagi nilainya dengan 2 (Field, 2005).
Analisis Regresi Spline (skripsi dan tesis)
Spline merupakan model polinom yang tersegmen atau terpotong-potong yang mulus dan dapat menghasilkan fungsi regresi yang sesuai dengan data. Polinomial tersegmen tersebut memiliki peranan penting dalam teori dan aplikasi statistika. Mengestimasi spline tergantung pada titik knot. Titik knot merupakan suatu titik perpaduan yang terjadi karena perubahan pola perilaku dari suatu fungsi pada selang yang berbeda. Fungsi 𝑓(𝑥𝑖) pada persamaan (2.5) nonparametrik merupakan fungsi regresi yang tidak diketahui bentuknya dan sifat pemulusnya, maka untuk mengestimasi 𝑓(𝑥𝑖) tersebut dapat digunakan model regresi spline. Fungsi spline pada suatu fungsi f dengan orde p dapat dinyatakan sebagai berikut: 𝑓(𝑥𝑖 ) = 𝛽0 + 𝛽1𝑥𝑖 1 + ⋯ + 𝛽𝑝𝑥𝑖 𝑝 + ∑ 𝛽(𝑝+𝑙)(𝑥𝑖 − 𝑘𝑙)+ 𝑟 𝑝 𝑙=1 𝑓(𝑥𝑖 ) = ∑ 𝛽𝑗𝑥𝑖 𝑗 + ∑ 𝛽(𝑝+𝑙)(𝑥𝑖 − 𝑘𝑙)+ 𝑟 𝑝 𝑙=1 𝑝 𝑗=0 (2.6) dengan k menyatakan banyaknya titik knot dan (𝑥𝑖 − 𝑘𝑙)+ 𝑝 menyatakan fungsi potongan (truncated) yang dapat dijabarkan sebagai berikut: (𝑥𝑖 − 𝑘𝑙)+ 𝑝 = { (𝑥𝑖 − 𝑘𝑙) 𝑝 , 𝑥𝑖 ≥ 𝑘𝑙 0, 𝑥𝑖 < 𝑘𝑙 (2.7) Bentuk matematis dari fungsi spline pada persamaan (2.6), dapat dinyatakan bahwa spline adalah potongan-potongan polinom yang berbeda digabungkan bersama titik knot 𝑘1, 𝑘2, 𝑘3, … . , 𝑘𝑟 untuk menjamin sifat kontinuitasnya.
Analisis Regresi Nonparametrik (skripsi dan tesis)
Regresi nonparametrik merupakan suatu metode statistika yang digunakan untuk mengetahui pola hubungan antara variabel prediktor dengan respons ketika tidak diperoleh informasi sebelumnya tentang bentuk fungsi regresinya atau tidak diketahui bentuk kurva regresinya. Fungsi dari model regresi nonparametrik dapat berbentuk apa saja, baik linear atau nonlinear. Misalkan variabel respons adalah y dan variabel prediktor adalah x untuk n pengamatan, model umum dari regresi nonparametrik adalah 𝑦𝑖 = 𝑓(𝑥𝑖 ) + 𝜀𝑖 ; 𝑖 = 1,2,3, … , 𝑛 (2.5) dengan 𝑦𝑖 adalah variabel respons, 𝑥𝑖 adalah variabel prediktor, 𝑓(𝑥𝑖) adalah fungsi regresi yang tidak diketahui bentuknya, dan 𝜀𝑖 adalah sisaan yang diasumsikan bebas dengan nilai tengah nol dan varians σ2 . Metode regresi nonparametrik dapat digunakan dengan mengabaikan asumsi-asumsi yang melandasi metode regresi parametrik. Fungsi regresi nonparametrik f diasumsikan mulus sehingga memiliki fleksibilitas yang tinggi dalam mengestimasi fungsi regresinya. Ada beberapa teknik dalam mengestimasi regresi dalam nonparametrik yaitu deret Fourier, spline, dan kernel. Pada subbab berikutnya akan dibahas analisis regresi spline
Analisis Regresi Parametrik (skripsi dan tesis)
Analisis regresi merupakan sebuah alat statistika yang digunakan untuk melihat hubungan antara variabel respons dengan satu atau lebih variabel prediktor. Analisis regresi pertama kali dikemukakan oleh seorang antropolog dan ahli meteorologi terkenal di Inggris yaitu Sir Francis Galton (1822-1911). Dalam model regresi terdiri atas dua variabel yaitu variabel independent (variabel bebas) disebut juga variabel prediktor yang biasanya dinotasikan dengan variabel 𝑥, dan variabel dependent (variabel tak bebas) disebut juga variabel respons yang biasanya dinotasikan dengan variabel 𝑦. Variabel 𝑥 dan 𝑦 tersebut merupakan dua variabel yang saling berkorelasi. Misalkan terdapat data berpasangan (𝑥𝑖 , 𝑦𝑖) untuk n pengamatan, maka hubungan antara variabel 𝑥𝑖 dan variabel 𝑦𝑖 dapat dinyatakan sebagai berikut: 𝑦𝑖 = 𝑓(𝑥𝑖 ) + 𝜀𝑖 ; 𝑖 = 1,2, … , 𝑛 (2.1) dengan 𝑦𝑖 adalah respons ke-i, 𝑓(𝑥𝑖) adalah fungsi regresi atau kurva regresi, serta 𝜀𝑖 adalah sisaan yang diasumsikan independent dengan nilai tengah nol dan variansi σ 2 . Regresi parametrik merupakan metode yang digunakan untuk mengetahui pola hubungan antara variabel respons dan prediktor apabila bentuk kurva regresinya diketahui Model regresi dengan variabel prediktor lebih dari satu (𝑥1, 𝑥2, 𝑥3, … , 𝑥𝑝) secara umum dapat dituliskan sebagai berikut: 𝑦𝑖 = 𝛽0 + 𝛽1𝑥𝑖1 + 𝛽2𝑥𝑖2 + 𝛽3𝑥𝑖3 + ⋯ + 𝛽𝑝𝑥𝑖𝑝 + 𝜀𝑖 ; 𝑖 = 1,2,3, … , 𝑛 (2.2) dengan 𝛽0, 𝛽1, 𝛽2, 𝛽3, … , 𝛽𝑝 adalah koefisien regresi. Model dapat pula disajikan dalam bentuk matriks yang dituliskan pada persamaan sebagai berikut: [ 𝑦1 𝑦2 ⋮ 𝑦𝑛 ] = [ 1 1 ⋮ 1 𝑥11 𝑥21 ⋮ 𝑥𝑛1 𝑥12 𝑥22 ⋮ 𝑥𝑛2 … … ⋱ … 𝑥1𝑝 𝑥2𝑝 ⋮ 𝑥𝑛𝑝] [ 𝛽0 𝛽1 ⋮ 𝛽𝑝 ] + [ 𝜀1 𝜀2 ⋮ 𝜀𝑛 ] atau 𝒚 = 𝒙𝜷 + 𝜺 (2.3) dengan 𝒚 = [ 𝑦1 𝑦2 ⋮ 𝑦𝑛 ], 𝒙 = [ 1 1 ⋮ 1 𝑥11 𝑥21 ⋮ 𝑥𝑛1 𝑥12 𝑥22 ⋮ 𝑥𝑛2 … … ⋱ … 𝑥1𝑝 𝑥2𝑝 ⋮ 𝑥𝑛𝑝], 𝜷 = [ 𝛽0 𝛽1 ⋮ 𝛽𝑝 ], dan 𝜺 = [ 𝜀1 𝜀2 ⋮ 𝜀𝑛 ] (2.4) dengan 𝒚 adalah vektor kolom untuk variabel respons berukuran 𝑛 × 1, 𝑥 adalah matriks konstanta berukuran 𝑛 × 𝑝, 𝜷 adalah vektor parameter berukuran 𝑝 × 1, dan 𝜺 adalah vektor peubah acak normal bebas dengan nilai harapan 𝐸{𝜺} = 0 dan matrik ragam 𝜎 2 {𝜺} = 𝜎 2 yang berukuran 𝑛 × 1
Uji Chi-Square (skripsi dan tesis)
Chi-square atau kai kuadrat (X2 ) merupakan salah satu jenis uji komparatif nonparametrik yang dilakukan pada dua variabel, dimana skala data kedua variabel adalah nominal atau ordinal. Dasar dari uji chi-square adalah membandingkan perbedaan antara frekuensi observasi dengan frekuensi ekspektasi atau frekuensi yang diharapkan. Frekuensi observasi adalah frekuensi yang nilainya didapat dari hasil percobaan. Sedangkan frekuensi harapan adalah frekuensi yang nilainya dapat dihitung secara teoritis. Perbedaan tersebut untuk meyakinkan apabila harga dari chi-square sama atau lebih besar dari suatu harga yang telah ditetapkan pada taraf signifikan tertentu. Uji chi-square sangat bermanfaat dalam melakukan analisis statistik apabila asumsi-asumsi yang dipersyaratkan untuk penggunaan statistik parametrik tidak dapat terpenuhi. Syarat-syarat dalam menggunakan uji ini adalah frekuensi responden atau sampel yang digunakan besar, karena ada beberapa syarat dimana chi-square dapat digunakan yaitu: a. Tidak ada cell dengan nilai frekuensi kenyataan (actual count) sebesar nol. b. Apabila bentuk tabel kontingensi 2×2, maka tidak boleh ada satu cell saja yang memiliki frekuensi harapan (expected count) kurang dari lima. c. Sedangkan apabila bentuk tabel lebih dari 2×2, maka jumlah cell dengan frekuensi harapan yang kurang dari lima tidak boleh lebih dari 20%. Adapun kegunaan dari uji chi-square sebagai berikut: a. Untuk mengetahui ada tidaknya asosiasi antara dua variabel. b. Untuk mengetahui homogenitas antar-sub kelompok. c. Untuk uji kenormalan data dengan melihat distribusi data. d. Untuk menganalisis data yang berbentuk frekuensi. e. Untuk menentukan besar kecilnya korelasi dari variabel-variabel yang dianalisis. Bentuk distribusi chi-square tergantung dari derajat kebebasan atau yang biasa dilambangkan d.f. (degree of freedom). Chi-square memiliki masing-masing nilai derajat kebebasan yaitu distribusi (kuadrat standard normal) yang merupakan distribusi chi-square dengan d.f. = 1 dan nilai variabel tidak bernilai negatif. Karakteristik dari chi-square yaitu nilainya selalu positif karena nilai chi-square adalah nilai kuadrat.
Crosstabs (skripsi dan tesis)
Crosstabs atau tabulasi silang merupakan suatu metode analisis deskriptif yang berbentuk tabel, dimana menampilkan tabulasi silang atau tabel kontingensi yang digunakan untuk mengidentifikasi serta mengetahui apakah ada korelasi atau hubungan sebab-akibat antara satu variabel dengan variabel yang lainnya ke dalam suatu matriks. Hasil crosstabs disajikan ke dalam suatu tabel dengan variabel yang tersusun sebagai kolom dan baris serta berisi nilai frekuensi dan persentase. Tabel yang dianalisis pada crosstabs ini adalah hubungan antara variabel dalam baris dengan variabel dalam kolom. Penyajian data pada umumnya adalah data kualitatif. Ciri dari penggunaan crosstabs yaitu data input yang pada umumnya berskala nominal atau ordinal. Pembuatan crosstabs dapat disertai dengan pengolahan atau perhitungan tingkat keeratan hubungan (asosiasi) antar variabel pada crosstabs. Alat statistik yang sering digunakan untuk menguji ada tidaknya hubungan antara baris dan kolom dari sebuah crosstabs adalah uji chi-square. Selain uji chi-square, ada beberapa alat uji lainnya yang dapat digunakan seperti kendall, kappa, dan lain sebagainya
Uji Tanda (Sign Test) (skripsi dan tesis)
Uji tanda atau sign test merupakan uji non-parametrik yang digunakan untuk menguji ada tidaknya perbedaan dari dua buah populasi yang saling berkorelasi, dimana datanya memiliki skala pengukuran ordinal. Metode analisis ini menggunakan data yang dinyatakan dalam bentuk tanda (+) positif dan (-) negatif dari perbedaan antara pengamatan yang berpasangan. Sedangkan nilai 0 tidak diikut sertakan dalam analisis karena nilai 0 berarti tidak terdapat perubahan sebelum dan sesudah perlakuan. Pada prinsipnya, uji tanda memiliki tujuan untuk menghitung selisih nilai dari kedua pasang sampel. Apabila Ho diterima, maka jumlah selisih pasangan data yang positif kurang lebih akan sama dengan pasangan data yang negatif, sehingga sangat diharapkan jumlah selisih pasangan data yang positif dan negatif adalah setengah dari total sampel yang ada. Sedangkan Ho ditolak, jika jumlah selisih pasangan data yang negatif dengan data yang positif memiliki perbedaan nilai yang sangat tingg
Ciri-Ciri Statistik Non-Parametrik (skripsi dan tesis)
Dalam menganalisis data tentunya harus mengetahui ciri-ciri dari statistik yang akan digunakan agar dapat lebih mudah dalam menentukan uji yang cocok untuk digunakan pada kasus tersebut. Berikut ciri-ciri dari statistik non-parametrik: a. Data tidak berdistribusi normal b. Umumnya data berskala nominal dan ordinal c. Umumnya dilakukan pada penelitian sosial d. Umumnya jumlah sampel kecil
Pengelompokan Kategori Statistik Non-Parametrik (skripsi dan tesis)
Dalam statistik non-parametrik terdapat pengelompokan yang didasarkan dari kriteria sampel yang diambil pada saat penelitian yaitu sampel tunggal, sampel independen, dan sampel dependen. Adapun penjelasan dari masing-masing kriteria sampel adalah sebagai berikut: a. Sampel Tunggal Sampel tunggal digunakan untuk menduga dan menguji hipotesis dari parameter yang ada, contohnya pengukuran nilai sentral. Pada statistik nonparametrik uji yang digunakan untuk menduga nilai sentral, seperti uji tanda (sampel tunggal) dan uji Wilcoxon. Selain itu, terdapat juga prosedur nonparametrik lainnya, antara lain uji binomial yang digunakan untuk pengukuran proporsi populasi, uji Trend untuk mengetahui kencenderungan dari populasi yang ada, dan uji Cox-Stuart untuk menguji data berdasarkan waktu. b. Sampel Independen Sampel independen memiliki kegunaan untuk membandingkan antara dua variabel yang terukur dari sampel yang bebas. Pengambilan sampel ini berasal dari dua populasi. Pada statistik parametrik dapat menggunakan uji t untuk membandingkan nilai mean dari dua kelompok independen, sedangkan alternatif pengujian dalam statistik non-parametrik dapat menggunakan uji, antara lain Wald-Wolfowitz Runs test, Mann-Whitney U-test, dan KolmogorovSmirnov Two-Sample test.
Namun, apabila ingin membandingkan lebih dari dua populasi maka digunakanlah analisis satu arah bertingkat dengan Median test dan Kruskal-Wallis test. c. Sampel Dependen Sampel dependen pada dasarnya digunakan untuk membandingkan dua variabel yang terukur dari sampel yang berhubungan. Dalam statistik nonparametrik, misalnya untuk mengetahui perbedaan produktivitas kerja, dengan melakukan pengukuran pada sampel pekerja sebelum mendapatkan pelatihan dengan sampel pekerja sesudah mendapatkan pelatihan. Hal seperti ini dapat dilakukan dengan menggunakan pengujian Sign Test dan Wilcoxon’s Matched Pairs Test. Namun jika variabel memiliki sifat yang dikotomi, maka dapat digunakan pengujian McNemar’s Chi-square Test. Selain itu, apabila ternyata terdapat lebih dari dua variabel yang diteliti maka pengujian yang tepat digunakan yaitu Friedman’s two-way analysis of variance dan Cochran Q test
Dasar Statistika (skripsi dan tesis)
Pada dasarnya statistika terbagi menjadi dua yakni stastika deskriptif dan statistika inferensial. Statistika inferensial terbagi menjadi dua yaitu statistik parametrik dan statistik non-parametrik. Statistik non-parametrik merupakan analisis yang tidak menggunakan parameter seperti yang terdapat pada statistik non-parametrik, misalnya: mean, standar deviasi, dan variansi. Statistik nonparametrik juga sering disebut dengan metode distribusi bebas. Statistik nonparametrik menjadi alternatif dari statistik parametrik ketika asumsi-asumsi yang mendasari dalam statistik parametrik tidak dapat terpenuhi, sebab metode ini tidak memerlukan asumsi atau mengabaikan asumsi-asumsi yang menjadi landasan metode statistika parametrik terutama yang berkaitan dengan distribusi normal. Selain itu, statistik non-parametrik digunakan pada data yang berskala nominal dan ordinal serta populasi yang bebas distribusi. Semua permasalahan statistik sebenarnya dapat diselesaikan dengan statistik non-parametrik. Namun harus dipahami bahwa tidak semua permasalahan statistik dapat diselesaikan dengan menggunakan statistik parametrik sehingga harus menggunakan statistik non-parametrik.
Software IBM SPSS (skripsi dan tesis)
Santoso (2010) berpendapat bahwa software SPSS dapat dijadikan sebagai alternatif pengguna untuk mengolah data dan menginterpretasi output dengan mudah dalam menyelesaikan permasalahan pada metode non-parametrik. SPSS (Statistical Product and Service Solution) merupakan program aplikasi bisnis yang berguna untuk melakukan perhitungan atau menganalisa data statistik dengan menggunakan komputer. Dalam SPSS yang perlu dilakukan untuk memulai menganalis data yaitu mendesain variabel yang akan dianalisis, memasukkan data, dan melakukan perhitungan sesuai dengan tahapan yang ada pada menu yang tersedia. SPSS memiliki berbagai macam fitur yang ditawarkan untuk mengolah data dalam berbagai kasus, seperti: a. IBM SPSS Data Collection : untuk pengumpulan data b. IBM SPSS Statistics : untuk menganalisis data c. IBM SPSS Modeler : untuk memprediksi trend d. IBM Analytical Decision Management : untuk pengambilan keputusan SPSS banyak diaplikasikan serta digunakan oleh pengguna di segala bidang bisnis, perkantoran, pendidikan, dan penelitian. Secara spesifik, pemanfaatan program ini digunakan untuk riset pemasaran, penilaian kredit, peramalan bisnis, penilaian kepuasan konsumen, pengendalian, serta pengawasan dan perbaikan mutu suatu produk. Keunggulan dari SPSS dibandingkan dengan program yang lainnya adalah kemudahan dalam memasukkan data, kemudahan dalam mengolah data dengan hanya memilih uji statistik yang sudah tersedia, cepat dalam menampilkan output, dan output mudah untuk dipahami, dibaca, dan dicetak. Selain itu, SPSS mampu mengakses data dari berbagai macam format data yang tersedia seperti base, lotus, access, text file, spreadsheet, bahkan mengakses database melalui ODBD (Open Data Base Connectivity) sehingga 18 data yang berbagai macam format dapat langsung terbaca SPSS yang selanjutnya untuk dianalisis. SPSS dapat menguji data yang berjenis data kualitatif maupun data kuantitatif. Informasi yang diberikan oleh SPSS sangatlah akurat, hal ini dapat dilihat dengan memperlakukan missing data secara tepat yaitu dengan memberi alasannya misalnya pernyataan atau pertanyaan yang tidak relevan dengan kondisi responden, pernyataan atau pertanyaan tidak dijawab oleh responden, maupun ada pernyataan atau pertanyaan yang memang harus dilompati. Statistik yang termasuk software dasar SPSS, yakni: a. Statistik Deskriptif (Frekuensi, Deskripsi, Tabulasi Silang, Penelusuran, dan Statistik Deskripsi Rasio) b. Statistik Bivariat (Rata-Rata, ANOVA, t-test, Korelasi (Bivariat, Persial, Jarak), dan NonParametrik Test) c. Prediksi Hasil Numerik (Regresi Linear) d. Prediksi untuk mengidentifikasi kelompok (Diskriminan, Analisis Cluster (Two-Step, K-means, Hierarkis), dan Analisis Faktor)
Sumber Data (skripsi dan tesis)
Berdasarkan sumbernya, data penelitian dapat dikelompokkan menjadi dua jenis yaitu:
a. Data Primer Merupakan data yang diperoleh atau dikumpulkan oleh peneliti secara langsung dari sumber data utama. Data primer biasa disebut juga data asli yang memiliki sifat up to date. Teknik yang dapat digunakan peneliti untuk mengumpulkan data primer dengan cara seperti wawancara, observasi, dan penyebaran kuesioner.
b. Data Sekunder Merupakan data yang diperoleh atau dikumpulkan oleh peneliti dari berbagai sumber yang telah ada. Data sekunder dapat diperoleh dari berbagai sumber seperti pusat statistik, buku, laporan, makalah, jurnal, dan lain sebagainya
Metode Pengambilan Sampel (skripsi dan tesis)
Sampling adalah cara pengumpulan data dengan hanya elemen sampel yang diteliti, hasilnya merupakan data perkiraan atau estimate, bukan data sebenarnya. Sedangkan teknik sampling adalah suatu teknik pengambilan sampel (Sugiyono, 2013). Alasan teknik sampling lebih sering digunakan karena lebih menghemat waktu, biaya, serta tenaga, terkadang tidak diketahui objek secara keseluruhan, dan sering terjadi kesalahan dalam pengumpulan data dikarenakan banyak objek atau elemen yang harus diteliti. Suatu keputusan yang didasarkan atas data perkiraan hasil penelitian sampel akan selalu menimbulkan resiko. Resiko ini tidak dapat dihindari namun hanya dapat diperkecil dengan jalan memperkecil kesalahan sampling yaitu dengan memilih sampling yang tepat yang dapat mewakili populasi dari sampel yang diambil. Pada dasarnya teknik sampling dapat dikelompokkan menjadi dua macam yaitu probability sampling dan non-probability sampling. a. Metode dalam probability sampling i. Simple Random Sampling ii. Proportionate Stratified Sampling iii. Disproportionate Stratified Random Sampling iv. Cluster Sampling 13 b. Metode dalam non-probability sampling i. Sampling Sistematis ii. Sampling Kuota iii. Sampling Insidental iv. Sampling Jenuh v. Purposive Sampling vi. Snowball Sampling
Kuesioner (skripsi dan tesis)
Kuesioner merupakan teknik pengumpulan data yang dilakukan dengan cara memberi suatu pernyataan atau pertanyaan tertulis kepada responden (Sugiyono, 2013). Kuesioner berdasarkan bentuknya terbagi menjadi dua jenis, yaitu: a. Kuesioner Tertutup Kuesioner yang menyajikan pertanyaan dan alternatif pilihan jawaban sehingga responden hanya dapat memberikan tanggapan yang terbatas pada pilihan yang telah diberikan. Contoh dari kuesioner tertutup ini yaitu penilaian pelayanan pada sebuah cafe dan diberikan beberapan alternatif pilihan jawaban seperti sangat baik, baik, cukup, dan buruk. b. Kuesioner Terbuka Kuesioner yang memberikan kebebasan bagi responden untuk memberikan jawaban atau tanggapan atas pertanyaan yang telah diberikan, biasanya responden dapat menulis sendiri jawabannya berupa uraian. Contoh dari kuesioner terbuka yaitu “menurut anda seberapa pentingkah penggunaan smartphone?”. Penggunaan kuesioner banyak digunakan oleh peneliti karena dianggap lebih efektif dan efisien untuk mengumpulkan data dari responden yang jumlahnya besar dan dalam ruang lingkup wilayah penelitian yang luas
Penentuan Ukuran Sampel (skripsi dan tesis)
Ukuran sampel merupakan banyaknya individu, subjek, atau elemen dari populasi yang diambil sebagai sampel. Menurut Sugiyono (2013) mendefinisikan populasi adalah wilayah generalisasi yang terdiri atas objek atau subyek yang memiliki kualitas dan karakteristik tertentu yang ditetapkan oleh peneliti untuk dipelajari dan ditarik kesimpulan. Sedangkan sampel adalah bagian dari beberapa anggota yang dipilih dari populasi (Sekaran dan Bougie, 2010). Apabila ukuran sampel yang diambil terlalu besar atau terlalu kecil maka akan menjadi masalah dalam penelitian. Sampel yang baik yaitu sampel yang memberikan pencerminan optimal atau dapat mewakili terhadap populasinya (representative). Berikut pendapat para ahli tentang ukuran sampel: a. Gay dan Diehl (1992) mengasumsikan bahwa semakin banyak sampel yang diambil maka akan semakin representative dan hasilnya dapat di genelisir atau dapat diterima, namun akan sangat bergantung pada jenis penelitiannya. i. Penelitian bersifat deskriptif maka sampel minimumnya sebesar 10% dari populasi. ii. Penelitan yang bersifat korelasional maka sampel minimumnya 30 subyek. iii. Penelitian kausal-perbandingan maka sampelnya sebanyak 30 subyek per grup. iv. Sedangkan penelitian ekperimental maka sampel minimumnya sebanyak 15 subyek per grup. b. Roscoe (1975) menentukan ukuran sampel yang tepat yaitu sebesar ≥30 dan ≤500 sampel dan jika sampel dipecah ke dalam sub-sampel maka ukuran sampel minimum 30 untuk setiap kategori yang ada. Sugiyono (2013) menambahkan bahwa untuk penentuan jumlah sampel dari populasi tertentu yang dikembangkan dari Isaac dan Michael untuk tingkat kesalahan sebesar 1%, 5%, dan 10%.
Statistik Nonparametrik (skripsi dan tesis)
- Pengertian
Statistik Non-Parametrik, yaitu statistik bebas sebaran (tidak mensyaratkan bentuk sebaran parameter populasi, baik normal atau tidak). Selain itu, statistik non-parametrik biasanya menggunakan skala pengukuran sosial, yakni nominal dan ordinal yang umumnya tidak berdistribusi normal.
- Syarat statistik non-parametrik
- Data tidak berdistribusi normal
- Umumnya data berskala nominal dan ordinal
- Umumnya dilakukan pada penelitian social
- Umumnya jumlah sampel kecil
- Contoh metode statistik non-parametrik :
- Uji tanda (sign test)
- Rank sum test (wilcoxon)
- Rank correlation test (spearman)
- Fisher probability exact test.
- Chi-square test, dll
- Keunggulan dan kelemahan statistik non-parametrik
- Keunggulan :
1) Tidak membutuhkan asumsi normalitas.
2) Secara umum metode statistik non-parametrik lebih mudah dikerjakan dan lebih mudah dimengerti jika dibandingkan dengan statistik parametrik karena ststistika non-parametrik tidak membutuhkan perhitungan matematik yang rumit seperti halnya statistik parametrik.
3) Statistik non-parametrik dapat digantikan data numerik (nominal) dengan jenjang (ordinal).
4) Kadang-kadang pada statistik non-parametrik tidak dibutuhkan urutan atau jenjang secara formal karena sering dijumpai hasil pengamatan yang dinyatakan dalam data kualitatif.
5) Pengujian hipotesis pada statistik non-parametrik dilakukan secara langsung pada pengamatan yang nyata.
6) Walaupun pada statistik non-parametrik tidak terikat pada distribusi normal populasi, tetapi dapat digunakan pada populasi berdistribusi normal.
- Kelemahan
1) Statistik non-parametrik terkadang mengabaikan beberapa informasi tertentu.
2) Hasil pengujian hipotesis dengan statistik non-parametrik tidak setajam statistik parametrik.
3) Hasil statistik non-parametrik tidak dapat diekstrapolasikan ke populasi studi seperti pada statistik parametrik. Hal ini dikarenakan statistik non-parametrik mendekati eksperimen dengan sampel kecil dan umumnya membandingkan dua kelompok tertentu
Statistik Parametrik (skripsi dan tesis)
- Pengertian
Statistik Parametrik, yaitu ilmu statistik yang mempertimbangkan jenis sebaran atau distribusi data, yaitu apakah data menyebar secara normal atau tidak.
Statistik parametrik digunakan untuk menguji hipotesis dan variabel yang terukur. Dengan kata lain, data yang akan dianalisis menggunakan statistik parametrik harus memenuhi asumsi normalitas. Pada umumnya, jika data tidak menyebar normal, maka data seharusnya dikerjakan dengan metode statistik non-parametrik, atau setidak-tidaknya dilakukan transformasi terlebih dahulu agar data mengikuti sebaran normal, sehingga bisa dikerjakan dengan statistik parametrik.
- Syarat-syarat statistik parametrik :
- Data dengan skala interval dan rasio
- Data menyebar/berdistribusi normal
- Contoh metode statistik parametrik :
- Uji-z (1 atau 2 sampel)
- Uji-t (1 atau 2 sampel)
- Korelasi pearson,
- Perancangan percobaan (one or two-wayanova parametrik), dll.
- Keunggulan dan kelemahan statistik parametrik
- Keunggulan
1) Syarat syarat parameter dari suatu populasi yang menjadi sampel biasanya tidak diuji dan dianggap memenuhi syarat, pengukuran terhadap data dilakukan dengan kuat.
2) Observasi bebas satu sama lain dan ditarik dari populasi yang berdistribusi normal serta memiliki varian yang homogen.
- Kelemahan
1) Populasi harus memiliki varian yang sama.
2) Variabel-variabel yang diteliti harus dapat diukur setidaknya dalam skala interval.
3) Dalam analisis varian ditambahkan persyaratan rata-rata dari populasi harus normal dan bervarian sama, dan harus merupakan kombinasi linear dari efek-efek yang ditimbulkan.
Kelemahan Tes Statistik Non Parametrik (skripsi dan tesis)
- Jika data telah memenuhi semua anggapan model statistik parametrik, dan jika pengukurannya mempunyai kekuatan seperti yang dituntut, maka penggunaan tes statistik non parametrik akan merupakan penghamburan data. Misal : kita ingat bahwa bila suatu tes statistik non parametrik memiliki kekuatan efisiensi besar, katakanlah 90%, ini berarti bahwa kalau semua syarat tes statistik parametrik dipenuhi, maka tes statistik parametrik yang sesuai akan efektif dengan sampel yang 10% lebih kecil daripada yang digunakan dalam tes statistik non parametrik.
- Belum ada satupun metode statistik non parametrik untuk menguji interaksi-interaksi dalam model analisis varian (ANOVA), kecuali kita berani membuat anggapan-anggapan khusus tentang aditivitas.
Contoh penggunaan statistik non parametrik seperti pada uji t pada parametrik digantikan menjadi uji Mannn Whitney ataupun Wilcoxon pada non parametrik dan uji F pada parametrik digantikan oleh uji Kruskal Wallis pada non parametrik, dll.
Keuntungan Tes Statistik Non Parametrik (skripsi dan tesis)
- Pernyataan kemungkinan yang diperoleh dari sebagian besar tes statistik non parametrik adalah kemungkinan-kemungkinan yang eksak, tidak peduli bagaimana bentuk distribusi populasi yang merupakan induk sampel-sampel yang kita tarik.
- Jika sampelnya sekecil N = 6, hanya tes statistik non parametrik yang dapat digunakan kecuali kalau sifat distribusi populasinya diketahui secara pasti.
- Terdapat tes statistik non parametrik untuk menggarap sampel-sampel yang terdiri dari observasi-observasi dari beberapa populasi yang berlainan. Tidak ada satupun di antara tes parametrik dapat digunakan untuk data semacam itu tanpa menuntut kita untuk membuat anggapan-anggapan yang nampak tidak realistis.
- Tes statistik non parametrik dapat untuk menggarap data yang pada dasarnya merupakan ranking dan juga untuk data yang skor-skor keangkaanya secara sepintas kelihatan memiliki kekuatan ranking. Jika data pada dasarnya berupa ranking atau bahkan data itu hanya bisa diikategorikan sebagai plus (+) atau minus (-), data tersebut dapat digarap dengan menggunakan statistik non parametrik.
- Metode statistik non parametrik dapat digunakan untuk menggarap data yang hanya merupakan klasifikasi semata, yakni yang diukur dalam skala nominal.
Pengertian Statistik Non-Parametrik (skripsi dan tesis)
Tes statistik non parametrik adalah tes yang modelnya tidak menetapkan syarat-syarat mengenai parameter-parameter populasi yang merupakan induk sampel penelitiannya. Tes non parametrik tidak menuntut pengukuran sekuat yang dituntut tes statistik parametrik. Sebagian besar tes non parametrik dapat diterapkan untuk data dalam skala ukur ordinal dan beberapa yang lain dapat diterapkan untuk data dalam skala ukur nominal.
Meskipun semua anggapan tes parametrik mengenai populasi dan syarat-syarat mengenai kekuatan pengukuran dipenuhi (5 poin syarat parametrik), kita ketahui bahwa dengan memperbesar ukuran sampel dengan banyak elemen yang sesuai dapat menggunakan suatu tes non parametrik sebagai ganti tes parametrik dengan masih mempertahankan kekuatan yang sama untuk menolak H0.
Statistik Parametrik (skripsi dan tesis)
Pengujian data melalui statistik parametrik disyarati dengan adanya sejumlah anggapan-anggapan yang kuat yang mendasari penggunaanya. Manakala anggapan-anggapan itu terpenuhi, pengujian-pengujian parametrik inilah yang paling besar kemungkinannya untuk menolak H0 ketika H0 salah. Artinya, kalau data penelitian dianalisis secara tepat dengan pengujian parametrik, pengujian tersebut akan lebih kuat dari pengujian mana pun dalam hal penolakan terhadap H0 jika H0 salah. Oleh karenanya dalam penggunaan pengujian statistik parametrik perlu dipenuhi beberapa unsur-unsur dari model pengujian dengan statistik parametrik, diantaranya :
- Objek pengamatan harus saling independen. Artinya pemilihan sembarang kasus dari populasi untuk dimasukan dalam sampel tidak boleh menimbulkan bias pada kemungkinan-kemungkinan bahwa kasus yang lain akan termasuk juga dalam sampel tersebut dan juga skor yang diberikan pada suatu kasus tidak boleh mempengaruhi skor yang diberikan kepada kasus lainnya.
- Objek pengamatan harus ditarik dari populasi yang berdistribusi normal.
- Populasi-populasi di mana objek pengamatan ditarik harus memiliki varians yang sama.
- Variabel-variabel yang terlibat harus setidaknya dalam skala interval, sehingga memungkinkan digunakannya penanganan secara ilmu hitung terhadap skor-skornya (menambah, membagi, menemukan rata-rata, dst)
- Rata-rata populasi normal dan bervarians sama itu harus juga merupakan kombinasi linier dari efek-efek yang ditimbulkan. Artinya, efek-efek itu harus bersifat penjumlahan. (khusus dalam analisis varians atau uji F)
Kalau kita cukup mempunyai alasan untuk percaya bahwa persyaratan tersebut terpenuhi oleh data yang sedang dianalisis, tentu kita akan memilih suatu tes statistik parametrik, untuk menganalisis data. Pemilihan ini adalah paling baik, sebab tes parametrik akan merupakan tes paling kuat untuk menolak H0 manakala H0 memang harus ditolak.
Contoh penggunaan statistik parametrik seperti pada uji t dan F, yang aplikasinya banyak diterapkan semisal pada analisi regresi, path analisis, rancangan percobaan, analisis faktor (CFA), struktural equation modeling (SEM), dll.
Metode AHP (skripsi dan tesis)
Data yang diperoleh diolah dan dianalisis sehingga dapat
memberikan suatu sistem kerja yang jelas. Metode yang dipakai dalam
pengolahan data adalah metode AHP, karena
1. AHP dapat mengarahkan proses pengambilan keputusan dengan
mengidentifikasi dan menimbang kriteria yang dipilih, menganalisis
data yang berhasil dikumpulkan dari kriteria tersebut dan tentunya
proses pengambilan keputusan dapat berlangsung lebih cepat dan
efisien (Saaty, 1991).
2. AHP mampu menciptakan suatu hasil yang representatif dengan
memadukan beberapa pendapat pakar. Dimana kualitas yang
dihasilkan tergantung pada ketepatan pemilihan pakar serta proses
penyusunan bobot yang dilakukan oleh peneliti.
3. Untuk memodelkan problema-problema tak terstruktur, baik dalam
bidang ekonomi, sosial, maupun sains manajemen.
4. Baik digunakan dalam memodelkan problema-problema dan
pendapat sedemikian rupa, dimana permasalahan yang ada telah
benar-benar dinyatakan secara jelas, dievaluasi, diperbincangkan
dan dprioritaskan untuk dikaji.
Penilaian dilakukan dengan cara membandingkan komponenkomponen tersebut secara berpasangan dengan nilai yang merupakan
skala komparasi yang dikeluarkan oleh Saaty (1991) sesuai dengan
penilaian sehingga membentuk matriks persegi (n x n). Dengan
menggunakan rumus matematika dalam proses hirarki analitik, data
hasil diolah untuk mengetahui konsistensi indeks dan konsistensi rasio
matrik pendapat individu. Jika matrik pendapat individu tersebut tidak
konsisten, maka dilakukan revisi pendapat setelah itu dilakukan
kembali pengolahan data hingga menghasilkan vektor prioritas sistem
untuk masing-masing alternatif.
Adapun langkah-langkah penggunaan metode AHP, yaitu pertama
menentukan tujuan dan memberi bobot bagi setiap kriteria. Kedua,
membuat pair-wise comparison. Ketiga, menentukan bobot relatif dari
setiap sub-kriteria pada setiap tingkat hirarki kriteria. Keempat,
menghitung tingkat bobot sub-kriteria. Kelima, menghitung
kekonsistenan dari hasil perhitungan.
Analisis SWOT (skripsi dan tesis)
Analisis SWOT kualitatif yang digunakan didasarkan pada
wawancara terbatas. Dalam SWOT dipetakan faktor internal yang terdiri
dari kekuatan dan kelemahan, serta faktor eksternal yang terdiri dari
peluang dan ancaman. Setelah mengumpulkan semua informasi yang
berpengaruh terhadap kondisi program pengembangan karir, tahap
selanjutnya adalah memanfaatkan semua informasi tersebut dalam
pemilihan alternatif strategi program pengembangan karir melalui talent
management. Alat yang digunakan adalah matrik SWOT (Tabel 3).
Matriks ini menggambarkan bagaimana peluang dan ancaman eksternal
yang dihadapi organisasi dapat disesuaikan dengan kekuatan dan
kelemahan yang dimilikinya.
matriks SWOT menghasilkan empat sel
kemungkinan strategi alternatif, yaitu:
1. Strategi S-O dibuat berdasarkan jalan pikiran yang ada yaitu dengan
memanfaatkan seluruh kekuatan untuk merebut dan memanfaatkan
peluang yang sebesar-besarnya.
2. Strategi S-T menggunakan kekuatan untuk menghindari atau
mengurangi dampak ancaman eksternal.
3. Strategi W-O diterapkan berdasarkan pemanfaatan peluang yang ada
dengan cara meminimalkan kelemahan yang ada.
4. Strategi W-T berusaha meminimalkan kelemahan yang ada, serta
menghindari ancaman.
Penentuan strategi yang dibangun melalui matriks SWOT memiliki 8
tahapan, yaitu:
1. Buat daftar peluang-peluang eksternal perusahaan.
2. Buat daftar ancaman-ancaman eksternal perusahaan.
3. Buat daftar kekuatan-kekuatan internal perusahaan.
4. Buat daftar kelemahan-kelemahan internal perusahaan.
5. Cocokan kekuatan internal dan peluang eksternal dan catat hasilnya
dalam sel strategi SO
6. Cocokan kelemahan internal dan peluang eksternal dan catat hasilnya
dalam sel strategi WO
7. Cocokan kekuatan internal dan ancaman eksternal dan catat hasilnya
dalam sel strategi ST
8. Cocokan kelemahan internal dan ancaman eksternal dan catat
hasilnya dalam strategi WT
Analytical Hierarchy Process (AHP) (skripsi dan tesis)
Analytical Hierarchy Process (AHP) pertama kali dikembangkan oleh
Thomas L. Saaty, seorang ahli matemtika dari univeristas Pittsburg, Amerika
Serikat, pada awal tahun 1970-an. AHP adalah metode pengambilan
keputusan yang termasuk dalam kategori complex decision (keputusan yang
pelik, rumit). AHP adalah alat bantu yang telah terbukti kemampuannya, dan
secara efektif dapat digunakan dalam complex decision process. Tidak hanya
itu AHP dapat mengarahkan proses pengambilan keputusan dengan
mengidentifikasi dan menimbang kriteria yang dipilih, menganalisis data
yang berhasil dikumpulkan dari kriteria tersebut, dan tentunya proses
pengambilan keputusan dapat berlangsung lebih cepat dan efisien. AHP
merupakan metode yang memodelkan prioritas permasalahan yang tidak
terstruktur seperti dalam bidang ekonomi, sosial, dan ilmu-ilmu manajemen.
Saaty (1991) menyatakan terdapat tiga prinsip AHP, yaitu:
1. Penyusunan hirarki, yaitu memecahkan persoalan menjadi unsur-unsur
yang terpisah
2. Penetapan prioritas, yaitu menentukan peringkat elemen-elemen menurut
kepentingannya.
3. Konsistensi logis, yaitu menjamin bahwa semua elemen dikelompokkan
secara logis dan diperingkatkan.
Tahapan paling penting dalam analisis adalah penilaian dengan teknik
komparasi berpasangan (pairwise comparison) terhadap elemen-elemen pada
suatu tingkat hirarki. Penilaian dilakukan dengan memberikan bobot numerik
dan membandingkan antara satu elemen dengan elemen lain berdasarkan skala komparasi yang telah ditetapkan . Tahap berikutnya adalah
melakukan sintesis terhadap hasil penilaian yang dilakukan untuk menentukan
elemen mana yang memiliki prioritas tertinggi dan terendah.
Metode Pemecahan masalah dengan menggunakan proses hirarki analitik
untuk menguraikan sistem yang komplek sehingga menjadi elemen-elemen
yang lebih sederhana. Menurut Saaty (1991), hirarki merupakan abstraksi
hubungan dan pengaruh antara elemen-elemen dalam struktur pada
keseluruhan sistem yang dipelajari. Abstraksi merupakan bentuk hubungan
antara elemen yang menggambarkan sistem secara keseluruhan.
Cara yang paling umum digunakan untuk menyusun hirarki adalah dengan
mempelajari literatur mengenai sistem yang dipelajari atau melakukan diskusi
dengan pihak atau orang yang berhubungan dengan sistem, karena pada
prakteknya tidak ada prosedur baku yang digunakan untuk menyusun hirarki.
Hirarki dalam metode ini, terdiri atas fokus, faktor, aktor, tujuan, dan alternatif
Keuntungan digunakannya hirarki dalam pemecahan masalah menurut
Saaty (1991) adalah:
1. Hirarki mewakili suatu sistem yang dapat menerangkan bagaimana
prioritas pada level yang lebih tinggi dapat mempengaruhi prioritas pada
level bawahnya.
2. Hirarki memberikan informasi rinci mengenai struktur dan fungsi dari
sistem pada level yang lebih rendah dan memberikan gambaran mengenai
aktor dan tujuan pada level yang lebih tinggi.
3. Sistem akan menjadi lebih efisien jika disusun dalam bentuk hirarki
dibandingkan dalam bentuk lain.
4. Bersifat stabil dan fleksibel dalam arti penambahan elemen pada struktur
yang telah tersusun baik tidak akan mengganggu penampilannya.
Analytical Hierarchy Process (AHP) memasukkan pertimbangan dan
nilai-nilai pribadi secara logis. Proses ini tergantung pada imajinasi,
pengalaman dan pengetahuan untuk menyusun hirarki suatu masalah, dan
tergantung pada logika, intuisi dan pengalaman untuk memberi pertimbangan.
Selanjutnya AHP menunjukkan bagaimana menghubungkan elemen-elemen
dari bagian lain untuk memperoleh hasil gabungan.
Saaty (1991) juga mengemukakan bahwa tahapan-tahapan proses dalam
AHP adalah menyusun hirarki, menetapkan prioritas dan prinsip konsistensi.
Penilaian dilakukan dengan teknik komparasi berpasangan terhadap elemenelemen keputusan pada suatu tingkat hirarki keputusan dengan menggunakan skala pengkuran yang dapat membedakan setiap pendapat serta mempunyai keteraturan, sehingga memudahkan transformasi dalam bentuk pendapat (kualitatif) ke dalam bentuk nilai angka (kuantitatif).
Respesifikasi Model (Respesification) Pada SEM (skripsi dan tesis)
Apabila model yang dihipotesiskan belum mencapai model yang fit, maka peneliti bisa melakukan respesifikasi model untuk mencapai nilai fit yang baik. Oleh karena itu, pendekatan teori yang benar ketika melakukan repesifikasi model ini dibutuhkan. Software LISREL juga menyediakan output modifikasi model yang membantu proses respesifikasi 28 model dalam hal meningkatkan fit dari suatu model. Modifikasi dilakukan dengan membuang atau menambah hubungan di antara variabel di dalam model SEM. Menurut Hair et al. (1998) ada 3 strategi pemodelan yang dapat dipilih dalam SEM, yaitu : a. Strategi Pemodelan Konfirmatori (Confirmatory Modelling Strategy) Pada strategi ini diformulasikan atau dispesifikasikan satu model tunggal, kemudian dilakukan pengumpulan data empiris untuk diuji signifikansinya. Pengujian ini akan menghasilkan suatu penerimaan atau penolakan terhadap model tersebut. Strategi ini tidak memerlukan respesifikasi. b. Strategi Kompetisi Model (Competing Models Strategy) Pada strategi ini beberapa model alternatif dispesifikasikan dan berdasarkan analisis terhadap satu kelompok data empiris dipilih salah satu model yang paling sesuai. Pada strategi ini respesifikasi hanya diperlukan jika model-model alternatif dikembangkan dari beberapa model yang ada. c. Strategi Pengembangan Model (Model Development Strategy) Pada strategi pemodelan ini suatu model awal dispesifikasikan dan data empiris dikumpulkan. Jika model awal tersebut tidak cocok dengan data empiris yang ada, maka model dimodifikasi dan diuji kembali dengan data yang sama. Beberapa model dapat diuji dalam proses ini dengan tujuan untuk mencari satu model yang selain cocok dengan data secara baik, tetapi juga mempunyai sifat bahwa setiap parameternya dapat diartikan dengan baik. Respesifikasi terhadap model dapat dilakukan berdasarkan theory-driven atau data-driven, meskipun demikian respesifikasi berdasarkan theory driven lebih dianjurkan (Hair et al 1998).
Uji Kecocokan Model Pada SEM (skripsi dan tesis)
Menurut Hair et al. (1998), SEM tidak mempunyai uji statistik tunggal terbaik yang dapat menjelaskan kekuatan dalam memprediksi sebuah model. Sebagai gantinya, peneliti mengembangkan beberapa kombinasi ukuran kecocokan model yang menghasilkan tiga perspektif, yaitu ukuran kecocokan model keseluruhan, ukuran kecocokan model pengukuran, dan ukuran kecocokan model struktural. Langkah pertama adalah memeriksa kecocokan model keseluruhan. Ukuran kecocokan model keseluruhan dibagi dalam tiga kelompok sebagai berikut: 1) Ukuran kecocokan mutlak (absolute fit measures), yaitu ukuran kecocokan model secara keseluruhan (model struktural dan model pengukuran) terhadap matriks korelasi dan matriks kovarians. Uji kecocokan tersebut meliputi: a. Uji Kecocokan Chi-Square Uji kecocokan ini mengukur seberapa dekat antara implied covariance matrix (matriks kovarians hasil prediksi) dan sample covariance matrix (matriks kovarians dari sampel data). Hipotesis yang digunakan adalah H0: Σ=Σ(θ) ; H1: Σ≠Σ (θ) , dengan 25 Σ adalah matriks kovarians sampel sedangkan Σ(θ) adalah matriks kovarians hasil prediksi dari model. Dalam prakteknya, P-value diharapkan bernilai lebih besar sama dengan 0,05 agar H0 dapat diterima yang menyatakan bahwa model adalah baik. Pengujian Chi-square sangat sensitif terhadap ukuran data. Yamin dan Kurniawan (2009) menganjurkan untuk ukuran sampel yang besar (lebih dari 200), uji ini cenderung untuk menolak H0. Namun sebaliknya untuk ukuran sampel yang kecil (kurang dari 100), uji ini cenderung untuk menerima H0. Oleh karena itu, ukuran sampel data yang disarankan untuk diuji dalam uji Chi-square adalah sampel data berkisar antara 100 – 200. b. Goodnees-Of-Fit Index (GFI) Ukuran GFI pada dasarnya merupakan ukuran kemampuan suatu model menerangkan keragaman data. Nilia GFI berkisar antara 0 – 1. Sebenarnya, tidak ada kriteria standar tentang batas nilai GFI yang baik. Namun bisa disimpulkan, model yang baik adalah model yang memiliki nilai GFI mendekati 1. Dalam prakteknya, banyak peneliti yang menggunakan batas minimal 0,9. c. Root Mean Square Error (RMSR) RMSR merupakan residu rata-rata antar matriks kovarians/korelasi teramati dan hasil estimasi. Nilai RMSR < 0,05 adalah good fit. d. Root Mean Square Error Of Approximation (RMSEA) RMSEA merupakan ukuran rata-rata perbedaan per degree of freedom yang diharapkan dalam populasi. Nilai RMSEA < 0,08 adalah good fit, sedangkan Nilai RMSEA < 0,05 adalah close fit. e. Expected Cross-Validation Index (ECVI) Ukuran ECVI merupakan nilai pendekatan uji kecocokan suatu model apabila diterapkan pada data lain (validasi silang). Nilainya didasarkan pada perbandingan antarmodel. Semakin kecil nilai, semakin baik. f. Non-Centrality Parameter (NCP) NCP dinyatakan dalam bentuk spesifikasi ulang Chi-square. Penilaian didasarkan atas perbandingan dengan model lain. Semakin kecil nilai, semakin baik. 2) Ukuran kecocokan incremental (incremental/relative fit measures), yaitu ukuran kecocokan model secara relatif, digunakan untuk perbandingan model yang diusulkan dengan model dasar yang digunakan oleh peneliti. Uji kecocokan tersebut meliputi: 26 a. Adjusted Goodness-Of-Fit Index (AGFI) Ukuran AGFI merupakan modifikasi dari GFI dengan mengakomodasi degree of freedom model dengan model lain yang dibandingkan. AGFI ≥ 0,9 adalah good fit, sedangkan 0,8 ≤ AGFI ˂ 0,9 adalah marginal fit. b. Tucker-Lewis Index (TLI) Ukuran TLI disebut juga dengan non normed fit index (NNFI). Ukuran ini merupakan ukuran untuk pembandingan antarmodel yang mempertimbangkan banyaknya koefisien di dalam model. TLI≥ 0,9 adalah good fit, sedangkan 0,8 ≤ TLI ˂ 0,9 adalah marginal fit. c. Normed Fit Index (NFI) Nilai NFI merupakan besarnya ketidakcocokan antara model target dan model dasar. Nilai NFI berkisar antara 0 – 1. NFI ≥ 0,9 adalah good fit, sedangkan 0,8 ≤ NFI ˂ 0,9 adalah marginal fit. d. Incremental Fit Index (IFI) Nilai IFI berkisar antara 0 – 1. IFI ≥ 0,9 adalah good fit, sedangkan 0,8 ≤ IFI ˂ 0,9 adalah marginal fit. e. Comparative Fit Index (CFI) Nilai CFI berkisar antara 0 – 1. CFI ≥ 0,9 adalah good fit, sedangkan 0,8 ≤ CFI ˂0,9 adalah marginal fit. f. Relative Fit Index (RFI) Nilai RFI berkisar antara 0 – 1. RFI ≥ 0,9 adalah good fit, sedangkan 0,8 ≤ RFI ˂ 0,9 adalah marginal fit. 3) Ukuran kecocokan parsimoni (parsimonious/adjusted fit measures), yaitu ukuran kecocokan yang mempertimbangkan banyaknya koefisien didalam model. Uji kecocokan tersebut meliputi: a. Parsimonious Normed Fit Index (PNFI) Nilai PNFI yang tinggi menunjukkan kecocokan yang lebih baik. PNFI hanya digunakan untuk perbandingan model alternatif. b. Parsimonious Goodness-Of-Fit Index (PGFI) Nilai PGFI merupakan modifikasi dari GFI, dimana nilai yang tinggi menunjukkan model lebih baik digunakan untuk perbandingan antarmodel. c. Akaike Information Criterion (AIC) 27 Nilai positif lebih kecil menunjukkan parsimoni lebih baik digunakan untuk perbandingan antarmodel. d. Consistent Akaike Information Criterion (CAIC) Nilai positif lebih kecil menunjukkan parsimoni lebih baik digunakan untuk perbandingan antarmodel. e. Criteria N (CN) Estimasi ukuran sampel yang mencukupi untuk menghasilkan adequate model fit untuk Chi-squared. Nilai CN > 200 menunjukkan bahwa sebuah model cukup mewakili sampel data. Setelah evaluasi terhadap kecocokan keseluruhan model, langkah berikutnya adalah memeriksa kecocokan model pengukuran dilakukan terhadap masing-masing konstrak laten yang ada didalam model. Pemeriksaan terhadap konstrak laten dilakukan terkait dengan pengukuran konstrak laten oleh variabel manifest (indikator). Evaluasi ini didapatkan ukuran kecocokan pengukuran yang baik apabila: 1. Nilai t-statistik muatan faktornya (faktor loading-nya) lebih besar dari 1,96 (t-tabel). 2. Standardized faktor loading (completely standardized solution LAMBDA) ≥ 0,5 . Setelah evaluasi terhadap kecocokan pengukuran model, langkah berikutnya adalah memeriksa kecocokan model struktural. Evaluasi model struktural berkaitan dengan pengujian hubungan antarvariabel yang sebelumnya dihipotesiskan. Evaluasi menghasilkan hasil yang baik apabila: 1. Koefisien hubungan antarvariabel tersebut signifikan secara statistik (t-statistik ≥ 1,96). 2. Nilai koefisien determinasi (R2 ) mendekati 1. Nilai R2 menjelaskan seberapa besar variabel eksogen yang dihipotesiskan dalam persamaan mampu menerangkan variabel endogen.
Estimasi Model (Model Estimation) Pada SEM (skripsi dan tesis)
Pada proses estimasi parameter, penentuan metode estimasi ditentukan oleh uji Normalitas data. Jika Normalitas data terpenuhi, maka metode estimasi yang digunakan adalah metode maximum likelihood dengan menambahkan inputan berupa covariance matrix dari data pengamatan. Bollen (1989) diacu oleh Wijanto (2008) menyarankan beberapa alternatif ketika terjadi non-normality atau excessive kurtosis, yaitu : a. Mentransformasikan variabel sedemikian rupa sehingga mempunyai multinormalitas yang lebih baik dan menghilangkan kurtosis yang berlebihan b. Menyediakan penyesuaian pada uji statistik dan kesalahan standar biasa sedemikian sehingga hasil modifikasi uji signifikan dari scale free adalah secara asimptotis benar. c. Menggunakan bootstrap resampling procedures. d. Menggunakan estimator alternatif yang menerima ketidaknormalan dan estimator tersebut asymptotically efficient. Weighted Least Square (WLS) estimator adalah salah satu di antara metode tersebut
Identifikasi Model (Model Identification) Pada SEM (skripsi dan tesis)
Untuk mencapai identifikasi model dengan kriteria over-identified model (penyelesaian secara iterasi) pada program LISREL dilakukan penentuan sebagai berikut: a. untuk konstrak laten yang hanya memiliki satu indikator pengukuran, maka koefisien faktor loading (lamda, λ ) ditetapkan 1 atau membuat error variance indikator pengukuran tersebut bernilai nol. b. untuk konstrak laten yang hanya memiliki beberapa indikator pengukuran (lebih besar dari 1 indikator), maka ditetapkan salah satu koefisien faktor loading (lamda, λ ) bernilai 1. Penetapan nilai lamda = 1 merupakan justifikasi dari peneliti tentang indikator yang dianggap paling mewakili konstrak laten tersebut. Indikator tersebut disebut juga sebagai variable reference. Jika tidak ada indikator yang diprioritaskan (ditetapkan), maka variable reference akan diestimasi didalam proses estimasi model.
Spesifikasi Model (Model Spesification) Pada SEM (skripsi dan tesis)
Pada tahap ini, spesifikasi model yang dilakukan oleh peneliti meliputi: a. mengungkapkan sebuah konsep permasalahan peneliti yang merupakan suatu pertanyaan atau dugaan hipotesis terhadap suatu masalah. b. mendefinisikan variabel-variabel yang akan terlibat dalam penelitian dan mengkategorikannya sebagai variabel eksogen dan variabel endogen. c. menentukan metode pengukuran untuk variabel tersebut, apakah bisa diukur secara langsung (measurable variable) atau membutuhkan variabel manifest (manifest variabel atau indikator-indikator yang mengukur konstrak laten). d. mendefinisikan hubungan kausal struktural antara variabel (antara variabel eksogen dan variabel endogen), apakah hubungan strukturalnya recursive (searah, X →Y) atau nonrecursive (timbal balik, X ↔Y) . e. langkah optional, yaitu membuat diagram jalur hubungan antara konstrak laten dan konstrak laten lainnya beserta indikator-indikatornya. Langkah ini dimaksudkan untuk memperoleh visualisasi hubungan antara variabel dan akan mempermudah dalam pembuatan program LISREL
Analisis Trend Linier (skripsi dan tesis)
Analisis trend merupakan metode analisis yang ditujukan untuk melakukan
suatu estimasi atau peramalan pada masa yang akan datang. Untuk melakukan
peramalan dengan baik maka dibutuhkan berbagai macam informasi (data)
yang cukup banyak. Selain itu, data perlu diamati dalam periode waktu yang
relatif cukup panjang. Dari hasil analisis tersebut dapat diketahui sampai
seberapa besar fluktuasi yang terjadi dan faktor-faktor apa saja yang
mempengaruhi perubahan tersebut. Dalam analisis time series yang paling
menentukan adalah kualitas atau keakuratan dari informasi atau data yang
diperoleh serta waktu atau periode data tersebut dikumpulkan (Ibrahim, 2009).
Analisis trend memperlihatkan kecendrungan ketersediaan lahan untuk usaha
tani padi dan kecenderungan konversi lahan sawah serta kemungkinan
pencetakan sawah baru di masa yang akan datang. Hasil proyeksi ini dapat
memperkirakan kebutuhan pangan masyarakat serta kebutuhan lain yang
berbasis pada penggunaan lahan. Melalui proyeksi ini dapat diperkirakan apa
yang terjadi di masa akan datang apabila tidak ada intervensi terhadap
kecenderungan yang ada saat ini (Ibrahim, 2009).
Menurut Pasaribu (1981), perhitungan trend linier dapat dilakukan dengan
analisis regresi linier sederhana menggunakan metode kuadrat terkecil (least
square method), yang dapat dinyatakan dalam bentuk persamaan Y = a + b (x)
Proyeksi ini menjelaskan hubungan antara satu variabel dengan variabel
lainnya. Trend linier dilihat melalui garis lurus pada grafik trend yang
dibentuk berdasarkan data proyeksi. Penyimpangan trend menunjukkan
besarnya kesalahan nilai proyeksi dengan data yang aktual. Tarigan (2006)
menambahkan bahwa proyeksi trend linier dengan metode analisis regresi
membuat asumsi bahwa kondisi yang terjadi di masa lampau akan terus
berlanjut ke masa yang akan datang.
Analisis Regresi Logistik Biner (skripsi dan tesis)
Menurut Jeffwu (1985) dalam Gantini (2005), model logistik merupakan
regresi yang saling dapat menggantikan satu dengan yang lain untuk
menganlisis peubah respon biner. Untuk itu, sering dibuat salah satu model
tanpa mempertimbangkan model lain yang mungkin akan menghasilkan model
yang lebih sesuai. Regresi logistik sering digunakan dalam menyelesaikan
masalah klasifikasi pada metode parametrik. Metode ini digunakan untuk
menggambarkan hubungan variabel dependen dengan variabel independen
bersifat kategori, kontinu atau kombinasi keduanya.
Ariyoso (2010) menjelaskan asumsi-asumsi dalam regresi logistik diantaranya:
a. Tidak mengasumsikan hubungan linier antar variabel dependen dan
independen.
b. Variabel dependen harus bersifat dikotomi (2 variabel).
c. Variabel independen tidak harus memiliki keragaman yang sama antar
kelompok variabel.
d. Sampel yang diperlukan dalam jumlah relatif besar, minimum dibutuhkan
hingga 50 sampel data untuk sebuah variabel prediktor.
Poedjiati (2008) mengemukakan bahwa regresi logit adalah prosedur
pemodelan yang diterapkan untuk memodelkan variabel respon (Y) yang
bersifat kategori berdasarkan satu atau lebih variabel prediktor (X) baik itu
yang bersifat kategori maupun kontinu. Dalam mengestimasi model regresi
dan pendugaan koefisien terdapat metode yang dapat digunakan yaitu metode
maximum likelihood, nonintractive weighted least square, dan discriminat
function anaysis.
Metode Simpleks Dalam Linier Programming (skripsi dan tesis)
Model pemrograman linier merupakan salah satu cara untuk mengatasi persoalan pengalokasian sumber daya-sumber daya yang terbatas pada beberapa aktivitas yang dilakukan dalam proses produksi sehingga memperoleh hasil yang optimal dengan tujuan untuk memaksimalkan keuntungan atau meminimalkan biaya. Dalam hal ini apabila perusahaan dihadapkan pada suatu persoalan pemrograman linier dalam pengambilan keputusan yang melibatkan lebih dari tiga variabel maka perusahaan harus dapat menentukan kombinasi produk yang akan diproduksi. Metode dalam model pemrograman linier yang dapat digunakan dalam persoalan tersebut adalah dengan menggunakan metode simpleks. Menurut Tjutju Tarliah Dimyati dan Ahmad Dimyati (2011:48) metode simpleks merupakan prosedur aljabar yang bersifat iteratif, yang bergerak selangkah demi selangkah, dimulai dari satu titik ektrim pada daerah fisibel (ruang solusi) menuju ke titik ekstrim yang optimum. Menurut Jay Heizer dan Barry Render yang diartikan oleh Dwinoegrahawatu Setyoningsih dan Indra Almahdy (2010:612) metode simpleks merupakan suatu algoritma atau serangkaian perintah yang digunakan untuk menguji titik sudut yang paling tinggi atau biaya yang paling rendah. Menurut Eddy Herjanto (2008:51) Metode simpleks adalah suatu metode yang secara sistematis dimulai dari suatu penyelesaian dasar yang fisibel ke penyelesaian dasar fisibel lainnya, yang dilakukan berulang-ulang (iterative) sehingga tercapai suatu penyelesaian optimum. Dalam memecahkan permasalahan pemrograman linier dengan menggunakan metode simpleks, dibutuhkan langkah-langkah pengerjaan yang harus disusun agar proses pengerjaannya dapat dilakukan dengan mudah. Metode simpleks adalah metode pemrograman linier yang digunakan untuk memecahkan masalah yang mempunyai minimum 3 (tiga) variabel.
Langkah–langkah penyelesaian dengan metode simpleks Henry Bustani (2005:10) :
1. Merubah fungsi pembatas dari pertidaksamaan menjadi persamaan dengan menambahkan slack variabel.
2. Memasukan persamaan kedalam tabel.
3. Mencari nilai Zj dan Cj – Zj.
4. Mencari nilai kolom kunci dengan cara : Pilih nilai Cj – Zj yang mempunyai nilai positif terbesar.
5. Mencari nilai baris kunci dengan cara :
1) Mencari indeks.
2) Pilih indeks dengan angka positif terkecil sebagai baris kunci.
6. Rubah basic variable dari baris kunci dengan basic variable yang terdapat diatas kolom kunci.
7. Mencari nilai baru baris kunci dengan cara : Membagi seluruh nilai pada baris kunci dengan angka kunci.
8. Mencari nilai baris selain baris kunci dengan cara : Baris baru = baris lama – (koefisien kolom kunci x nilai baru baris kunci).
9. Melanjutkan perbaikan – perbaikan dengan cara evaluasi Cj – Zj: bila Cj – Zj masih terdapat nilai positif, maka belum optimal, ulangi hingga menemukan nilai semua negatif.
Metode Grafik Dalam Linier Programming (skripsi dan tesis)
Seperti yang diketahui sebelumnya, bahwa model pemrograman linier merupakan salah satu cara yang dapat digunakan dalam mengatasi persoalan pengalokasian sumber daya-sumber daya yang terbatas dalam proses produksi. Apabila produk yang dihasilkan perusahaan lebih dari satu atau maksimal dua maka perusahaan harus bisa mengambil keputusan dalam menentukan kombinasi produk yang akan diproduksi. Metode yang dapat digunakan dalam metode pemrograman linier untuk mengatasi persoalan tersebut adalah dengan menggunakan metode grafik. Menurut Tjutju Tarliah Dimyati dan Ahmad Dimyati (2011:38) cara grafik dapat dipergunakan apabila persoalan program linier yang akan diselesaikan hanya mempunyai dua buah variabel. Menurut Jay Heizer dan Barry Render yang diartikan oleh Dwianoegrahwati Setyoningsih dan Indra Almahdy (2010:591) pendekatan solusi secara grafik adalah sebuah cara untuk memetakan sebuah solusi permasalahan dua variabel pada suatu grafik. Menurut Eddy Herjanto (2008:48) metode grafik pemecahan persoalan dengan yang mempunyai 2 variabel keputusan saja dengan membuat persamaan batasan sehinga memperoleh daerah fisibel bagi nilai-nilai variabelnya. Metode grafik adalah metode pemrograman linier yang digunakan untuk memecahkan masalah maksimal 2 (dua) variabel menurut Tjutju Tarliah Dimyati dan Ahmad Dimyati (2011:46). Langkah–langkah metode grafik :
1. Menentukan variabel keputusan.
2. Memformulasikan ke dalam dari fungsi tujuan dan fungsi pembatas.
3. Gambarkan dalam grafik variabel – variabel dalam fungsi pembatas.
4. Mencari nilai titik yang paling optimal dari fisibel area (daerah yang fisibel) atau yang tidak melewati pembatas kendala.
Rumusan atau Formulasi Pemrograman Linier (skripsi dan tesis)
Sebelum melakukan penyelesaian dengan pemrograman linier hal yang harus dilakukan terlebih dahulu yaitu dengan cara merumuskan permasalahan yang ada dengan aturan yang berlaku dalam pemrograman linier yaitu menentukan fungsi tujuan (objective function) dan fungsi kendala atau batasan (constraint). Seperti yang dijelaskan oleh Henry Bustani (2005:7) dengan merumuskan pemrograman linier sebagai berikut :
1. Formulasi pemrograman linier hanya akan mempunyai fungsi tujuan maksimasi atau minimasi.
2. Fungsi tujuan untuk keuntungan, pendapatan (revenue), dan sejenisnya adalah maksimal. Sedangkan fungsi tujuan untuk biaya dan waktu biasanya adalah minimasi. 3. Untuk kapasitas produksi atau sumber daya yang terbatas, tanda batasan yang digunkan biasanya “≤” atau “=” tergantung kondisi. Untuk tanda “≤”, sumber daya yang digunakan dapat lebih kecil atau sama dengan ketersediaan sumber daya tersebut. Sedangkan untuk tanda “=” sumber daya yang dugunakan harus sama dengan ketersediaan sumber daya tersebut. Karena itu, penggunaannya tergantung pada kondisi di lapangan.
4. Untuk permintaan akan sumber daya, tanda batasan yang digunakan biasanya “≥” atau “=”, tergantung dari kondisi. Untuk tanda “≥” sumber daya yang diperlukan dapat lebih besar atau sama dengan kebutuhan sumber daya tersebut. Karena itu, penggunaannya tergantung pada kondisi di lapangan.
5. Untuk fungsi tujuan maksimasi maka fungsi kendala harus mempunyai minimal satu fungsi yang mempunyai tanda batasan “≤” atau “=” kerana apabila tidak maka solusi yang didapat adalah unbound solution. 6. Untuk tujuan minimasi, maka fungsi kendala harus mempunyai minimal satu fungsi yang mempunyai tanda batasan “≥” atau “=” karena apabila tidak maka solusi yang didapat adalah unbound solution
Model Pemrograman Linier (skripsi dan tesis)
Dalam perumusan masalah dengan menggunakan pemrograman linier, hal terpenting yang perlu dilakukan adalah mencari tahu tujuan penyelesaian masalah dan apa penyebab masalah tersebut. Maka dari itu menurut Tjutju Tarliah Dimyati dan Ahmad Dimyati (2011:18) pemrograman linier mempunyai bentuk dan susunan dari persoalan yang akan dipecahkan dengan menggunakan karakteristik– karakteristik yang digunakan dalam persoalan program linier, yaitu :
1. Variabel keputusan adalah variabel yang menguraikan secara lengkap keputusan-keputusan yang akan dibuat.
2. Fungsi tujuan (objektive function) adalah fungsi yang tujuan atau sasaran didalam model pemrograman linier yang berkaitan dengan pengaturan secara optimal sumber daya-sumber daya untuk memperoleh keuntungan maksimal atau biaya minimal.
3. Fungsi pembatas (contrain function) merupakan bentuk penyajian secara matematis batasan-batasan kapasitas yang tersedia yang akan dialokasikan secara optimal keberbagai kegiatan. ]4. Pembatas Tanda Pembatas tanda adalah pembatas yang menjelaskan apakah variabel keputusannya diasumsikan hanya berharga nonnegative atau variabel keputusannya tersebut boleh berharga positif, boleh juga negatif (tidak terbatas dalam tanda).
Pengertian Linier Programming (skripsi dan tesis)
Pemrograman linier (linier programming) adalah teknik pengambilan keputusan untuk memecahkan masalah pengalokasian sumber daya yang terbatas diantara berbagai kepentingan seoptimal mungkin. Teknik ini dikembangkan oleh L. V. Kantorovich, seorang ahli matematik dari Rusia, pada tahun 1939. Pemrograman linier merupakan salah satu metode dalam riset operasi yang memungkinkan para manajer dapat mengambil keputusan dengan menggunakan pendekatan analisis kuantitatif. Teknik ini telah diterapkan secara luas pada berbagai persoalan dalam perusahaan, untuk menyelesaikan masalah yang berkaitan dengan penugasan karyawan, penggunaan mesin, distribusi dan pengangkutan, penentuan kapasitas produk, maupun dalam menentukan portofolio investasi. Menurut Jay Heizer dan Barry Rander yang diartikan oleh Dwianoegrahwati Setyoningsih dan Indra Almahdy (2010:658) sebuah teknik matematik yang didesain untuk membantu para manajer operasi dalam merencanakan dan membuat keputusan yang diperlukan untuk mengalokasikan sumber daya.
Menurut John Beigel (2009:139) linier programming is mathematically possible to eliminate the barriers that are Linier and solve the problems of relatively large. Menurut Tjutju Tarliah Dimyati dan Ahmad Dimyati (2011:17) pemrograman linier adalah perencanaan aktivitas-aktivitas untuk memperoleh suatu hasil yang optimum, yaitu suatu hasil yang mencapai tujuan terbaik diantara seluruh alternatif yang fisibel. Menurut Eddy Herjanto (2008:43) mengemukakan bahwa pemrograman Linier (linier programming) adalah teknik pengambilan keputusan untuk memecahkan masalah mengalokasikan sumber daya yang terbatas diantara berbagai kepentingan seoptimal mungkin. Karena penggunaannya semakin meluas, teknik pemrograman linier pun mengalami perkembangan. Sejak analisis dilakukan dengan cara yang sederhana baik aljabar maupun grafis untuk kasus sederhana kini teknik ini bisa digunakan untuk kasus yang memiliki tingkat kompleksitas yang tinggi dengan ratusan bahkan ribuan variabel dengan ditemukannya metode simpleks.
Metode simpleks dikembangkan oleh George B. Dantzig pada tahun 1947, yang merupakan metode yang paling luas dipakai dalam pemrograman linier. Perkembangan komputer digital elektronik dengan kemampuannya untuk melakukan kalkulasi hitungan yang jauh lebih cepat dari cara manual sangat membantu dalam pengunaan teknik ini. Tjutju Tarliah Dimyati – Ahmad Dimyati (2011:26) mengemukakan dalam menggunakan model pemrograman linier, diperlukan beberapa asumsi sebagai berikut :
1. Asumsi Kesebandingan (proportionality)
1) Kontribusi setiap variabel keputusan terhadap fungsi tujuan adalah sebanding dengan nilai variabel keputusan.
2) Kontribusi suatu variabel keputusan terhadap ruas kiri dari setiap pembatas juga sebanding dengan nilai variabel keputusan.
2. Asumsi Penambahan (additivity)
1) Kontribusi setiap variabel keputusan terhadap fungsi tujuan bersifat tidak bergantung pada nilai dari variabel keputusan yang lain.
2) Kontribusi suatu variabel keputusan terhadap ruas kiri dari setiap pembatas bersifat tidak bergantung pada nilai variabel keputusan yang lain.
3. Asumsi Pembagian (divisibility)
Dalam persoalan pemrograman linier, variabel keputusan boleh diasumsikan berupa bilangan pecahan.
4. Asumsi Kepastian (certainty)
Setiap parameter, yaitu koefisien fungsi tujuan, ruas kanan, dan koefisien teknologis, diasumsikan dapat diketahui secara pasti. Suatu masalah pemrograman hanya dapat dirumuskan ke dalam persoalan pemrograman linier apabila asumsi–asumsi diatas sudah terpenuhi
Ruang Lingkup Manajemen Operasi (Skripsi dan tesis)
Ruang lingkup manajemen produksi dan operasi menurut K. M Starr (dalam Manahan P. Tampubolon 2014:7) yaitu mencakup perancangan atau penyiapan sistem produksi dan operasi, serta pengoperasian dari sistem produksi dan operasi. Pembahasan dalam perancangan atau desain dari sistem produksi dan operasi meliputi:
1. Seleksi dan rancangan atau desain hasil produksi (produk)
Kegiatan produksi dan operasi harus dapat menghasilkan produk, berupa barang atau jasa, secara efektif dan efisien, serta dengan mutu atau kualitas yang baik. Oleh karena itu setiap kegiatan produksi dan operasi harus dimulai dari penyeleksian dan perancangan produk yang akan dihasilkan. Kegiatan ini harus diawali dengan kegiatan-kegiatan penelitian atau riset, serta usahausaha pengembangan produk yang sudah ada. Dengan hasil riset dan pengembangan produk ini, maka diseleksi dengan diputuskan produk apa yang akan dihasilkan dan bagaimana desain dari produk itu, yang menggambarkan pada spesifikasi dari produk tersebut. Untuk penyeleksian dan perancangan produk, perlu diterapkan konsep-konsep standarisasi, simplifikasi dan spesialisasi. Akhirnya dalam pembahasan ini perlu dikaji hubungan timbal balik yang erat antara seleksi produk dan rancangan produk dengan kapasitas produk dan operasi.
2. Seleksi dan perancangan proses dan peralatan.
Setelah produk didesain, maka kegiatan yang harus dilakukan untuk merealisasikan usaha untuk menghasilkan usahanya adalah menentukan jenis proses yang akan dipergunakan serta peralatannya. Dalam hal ini kegiatan harus dimulai dari penyeleksian dan pemilihan akan jenis proses yang akan dipergunakan, yang tidak terlepas dari produk yang akan dihasilkan. Kegiatan selanjutnya adalah menentukan teknologi dan peralatan yang akan dipilih dalam pelaksanaan kegiatan produksi tersebut. Penyeleksian dan penentuan peralatan dipilih, tidak hanya mencakup mesin dan peralatan tetapi juga mencakup bangunan dan lingkungan kerja.
3. Pemilihan lokasi dan site perusahaan dan unit produksi.
Kelancaran produksi dan operasi perusahaan sangat dipengaruhi oleh kelancaran mendapatkan sumber-sumber bahan dan masukan (input), serta ditentukan pula oleh kelancaran dan biaya penyampaian atau suplai produk yang dihasilkan berupa barang jadi atau jasa ke pasar. Oleh karena itu untuk menjamin kelancaran, maka sangat penting peranan dari pemilihan lokasi dan site tersebut, perlu diperhatikan faktor jarak, kelancaran dan biaya pengangkutan dari sumber-sumber bahan dan masukan (input), serta biaya pengangkutan dari barang jadi ke pasar.
4. Rancang tata letak (lay-out) dan arus kerja atau proses.
Kelancaran dalam proses produksi dan operasi ditentukan pula oleh salah satu faktor yang terpenting didalam perusahaan atau unut produksi, yaitu rancangan tata letak (lay-out) dan arus kerja atau proses. Rancangan tata letak harus mempertimbangkan beberapa faktor, kerja optimalisasi dari waktu pergerakan dalam proses, kemungkinan kerusakan yang terjadi karena pergerakan dalam proses akan meminimalisasi biaya yang timbul dari pergerakan dalam proses atau material handling.
5. Rancangan tugas pekerja.
Rancangan tugas pekerjaan merupakan bagian yang intergal dari rancangan sistem. Dalam melaksanakan fungsi produksi dari operasi, maka organisasi kerja harus disusun, karena organisasi kerja sebagai dasar pelaksanaan tugas pekerjaan, merupakan alat atau wadah kegiatan yang hendaknya dapat membantu pencapaian tujuan perusahaan atau unit produksi dan operasi tersebut. Rancangan tugas pekerjaan harus merupakan salah satu kesatuan dari human engineering, untuk menghasilkan rancangan kerja yang optimal. Disamping itu dalam penyusunan rancangan tugas pekerjaan yang harus pula memperhatikan kelengkapan tugas yang terkait dengan variabel tugas dalam stuktur teknologi, dan mutu atau kualitas suasana kerja yang ditentukan oleh variabel manusia.
6. Strategi produksi dan operasi serta pemilihan kapasitas.
Sebenarnya rancangan sistem produksi dan operasi harus disusun dengan landasan strategi produksi dan operasi yang disiapkan terlebih dahulu. Dalam strategi produksi dan operasi harus terdapat pernyataan tentang maksud dan tujuan dari produksi dan operasi, serta misi kebijakan-kebijakan dasar atau kunci untuk lima bidang, yaitu proses, kapasitas, persediaan, tenaga kerja, dan mutu atau kualitas. Semua hal tersebut merupakan landasan bagi penyususnan starategi produksi dan operasi, maka ditentukanlah pemilihan kapasitas yang akan dijalankan dalam bidang produksi dan operasi. Ruang lingkup manajemen operasi disini menjelaskan bahwa sebelum perusahaan ingin menghasilkan produk dengan mutu yang baik, harus melalui tahapan penelitian dan riset tentang bagaimana perancangan dan penyeleksian dari produk yang ingin dihasilkan
Pengertian Manajemen Operasi (skripsi dan tesis)
Manajemen operasi merupakan usaha-usaha pengelolaan secara optimal penggunaan sumber daya-sumber daya (atau sering disebut faktor-faktor produksi) tenaga kerja, mesin-mesin, peralatan, bahan mentah dan sebagainya. Dalam proses tranformasi bahan mentah dan tenaga kerja menjadi berbagai produk atau jasa. Roger G. Schroeder, Susan Meyer Goldstein and M. Johnny Rungtusanatham (2011:5) menyatakan operational management is the operation function of an organization is responsible for producing and delivering goods or services of value to customers of the organization. Menurut K. M Starr (dalam Manahan P. Tampubolon 2014:5) : Manajemen operasi merupakan proses konversi, dengan bantuan fasilitas seperti : tanah, tenaga kerja, modal dan manajemen masukan (input) yang diubah menjadi keluaran (output) yang diinginkan, berupa barang dan jasa atau layanan. Menurut Elwood S. Buffa (dalam Eddy Herjanto 2008:2) : Terdapat unsur-unsur pokok dari definisi manajemen operasi yaitu kontinyu dan efektif. Kontinyu, maksudnya keputusan manajemen tidak merupakan suatu tindakan sesaat melainkan tindakan yang berkelanjutan atau suatu proses yang kontinyu. Efektif berarti segala pekerjaan harus dapat dilakukan secara tepat dan sebaik-baiknya, serta mencapai hasil sesuai dengan yang diharapkan. Dari beberapa definisi tersebut penulis mengartikan bahwa manajemen operasi adalah semua usaha yang mengkoordinasikan dan memanfaatkan sumber daya atau faktor-faktor produksi seperti bahan mentah, tenaga kerja, energi, modal dan informasi yang ada dan dimiliki oleh perusahaan. Kemudian melalui proses transformasi, masukan-masukan atau input-input diubah menjadi output yaitu 15 berupa produk barang dan jasa, serta suatu pengambilan keputusan mengenai pengelolaan yang optimal dengan penggunaan faktor-faktor produksi dalam proses transformasi input menjadi output yang ditentukan oleh organisasi. Berdasarkan beberapa definisi manajemen operasi diatas penulis mengartikan manajemen operasi adalah sebuah fungsi bisnis atau fungsi operasi yang berperan menghasilkan barang dan atau jasa atau kombinasinya melalui proses transformasi dari sumber daya produksi menjadi keluaran yang diinginkan sehingga dapat memberikan nilai kepada pelanggan
Manajemen Operasi (skripsi dan tesis)
Manajemen operasi didalamnya berisi kegiatan menciptakan barang dan jasa yang ditawarkan perusahaan kepada konsumen. Melalui kegiatan manajemen operasi, segala sumber daya masukan perusahaan diintegrasikan untuk menghasilkan output yang memiliki nilai tambah. Kegiatan operasi merupakan kegiatan kompleks, yang mencakup tidak saja pelaksanaan fungsi-fungsi manajemen dalam mengkoordinasikan berbagai kegiatan dalam mencapai tujuan operasi, tetapi juga mencakup kegiatan teknis untuk menghasilkan suatu produk yang memenuhi spesifikasi yang diinginkan, manajemen operasi perlu dimiliki oleh semua pihak yang terlibat langsung dalam proses pembuatan produk sesuai dengan perannya masing-masing.
Pengertian Manajemen (skripsi dan tesis)
Manajemen adalah suatu ilmu yang didalamnya menjelaskan bagaimana mencapai suatu tujuan melalui kerjasama tim antara pemimpin dan yang dipimpin. Manajemen oleh sebagian orang diartikan sebagai seni karena dalam menjalankannya diperlukan keahlian dan keterampilan tertentu. Berikut adalah pengertian manajemen dari beberapa ahli : Menurut Steven P. Robbins (2011:6) menyatakan bahwa management is the process of coordinating work activities so that they are completed efficiently and effectively with the though other people.
Menurut Jain R. K dan Triandis H.C (dalam Melayu S. P Hasibuan 2010:10) manajemen adalah ilmu dan seni mengatur proses pemanfaatan sumber daya manusia dan sumber-sumber lainnya secara efektif dan efisien untuk mencapai suatu tujuan tertentu. Menurut Joseph G. Monks (dalam T. Hani Handoko 2012:10) : Manajemen adalah bekerja dengan orang-orang untuk menentukan, menginterpretasikan, dan mencapai tujuan-tujuan organisasi dengan pelaksanaan fungsi-fungsi perencanaan, pengorganisasian, penyusunan personalia, pengarahan, kepemimpinan dan pengawasan. Berdasarkan dari beberapa pengertian ahli dapat diartikan bahwa manajemen adalah proses pengkoordinasian seluruh kegiatan kerja sehingga menjadi efektif dan efisien dalam mencapai tujuan organisasi.
Himpunan Fuzzy (skripsi dan tesis)
Pada himpunan tegas (crisp), nilai keanggotaan suatu item x dalam
suatu himpunan A, yang sring ditulis dengan µA(X), memiliki dua
kemungkinan, yaitu (Kusumadewi):
Satu (1), yang berarti bahwa suatu item menjadi anggota dalam
suatu himpunan, atau
Nol (0), yang berarti bahwa suatu item tidak menjadi anggota
dalam suatu himpunan.
Menurut Kusumadewi (2010), ada beberapa hal yang perlu
diketahui dalam memahami system fuzzy, yaitu:
1. Variabel Fuzzy
Variabel Fuzzy merupakan variabel yang hendak dibahas dalam
suatu system fuzzy. Contoh: umur, temperature, permintaan,
dsb.
2. Himpunan Fuzzy
Himpunan fuzzy merupakan suatu grup yang mewakili suatu
kondisi atau keadaan tertentu dalam suatu variabel fuzzy.
3. Semesta Pembicara
Semesta pembicara adalah keseluruhan nilai yang
diperbolehkan untuk dioperasikan dalam suatu variabel fuzzy.
4. Domain
Domain himpunan fuzzy adalah keseluruhan nilai yang
diizinkan dalam semesta pembicara dan boleh dioperasikan
dalam suatu himpunan fuzzy.
Linear Programming (skripsi dan tesis)
Pemrograman linear adalah sebuah metode matematis yang
berkarakteristik linear untuk menemukan suatu penyelesaian optimal
dengan cara memaksimumkan atau meminimumkan fungsi tujuan
terhadap satu susunan kendala (Siswanto,2006).
Pemrograman linear menggunakan model matematika untuk
menggambarkan suatu masalah. Sifat linear di sini berarti semua
fungsi matematika harus berupa fungsi linear. Kata pemrograman
disini bukan berarti program komputer, melainkan perencanaan.
Pemrograman linier meliputi perencanaan perencanaan aktivitas
untuk mendapatkan hasil maksimal, yaitu sebuah hasil yang mencapai
tujuan terbaik (menurut model matematika) di antara semua
kemungkinan alternative yang ada (Hillier, 2005)
Model pemrograman linear mempunyai tiga unsur utama yaitu;
Variabel Keputusan
Adalah variabel persoalan yang akan mempengaruhi nilai tujuan
yang akan mempengaruhi nilai tujuan yang hendak dicapai. Di
dalam proses pemodelan, penemuan variabel keputusan tersebut
harus dilakukan terlebih dahulu sebelum merumuskan fungsi
tujuan dan kendala-kendalanya.
Fungsi Tujuan
Dalam model pemrograman linear, tujuan yang hendak dicapai
harus diwujudkan ke dalam sebuah fungsi matematika linear.
Selanjutnya, fungsi tersebut dimaksimumkan atau diminumkan
terhadap kendala-kendala yang ada.
Fungsi Kendala
Manajemen menghadapi berbagai kendala untuk mewujudkan
tujuan-tujuannya. Kenyataan tentang eksistensi kendala-kendala
tersebut selalu ada, misal:
– Keputusan untuk meningkatkan volume produksi dibatasi oleh
factor-faktor seperti kemampuan mesin, jumlah sumber daya
manusia dan teknologi yang tersedia.
– Manajer produksi harus menjaga tingkat produksi agar
permintaan pasar tepenuhi.
– Agar kualitas produk yang dihasilkan memenuhi standar
tertentu maka unsur bahan baku yang digunakan harus
memenuhi kualifikasi minimum.
– Likuiditas menjadi pertimbangan bank dalam pencairan kredit
– Peraturan pemerintah dan perundang-undangan mengatur
organisasi perusahaan dalam hal tertentu, misalnya system
perpajakan, ketentuan kandungan unsur tertentu di dalam suatu
produk, tingkat polusi, keharusan bagi pabrik susu bubuk untuk
menampung produksi susu KUD, dan lain-lain.
Kendala dengan demikian dapat diumpamakan sebagai suatu
pembatas terhadap kumpulan keputusan yang mungkin dibuat
dan harus dituangkan ke dalam fungsi matematika linear. Dalam
hal ini, sesuai dengan dalil-dalil matematika, ada tiga macam
kendala, yaitu:
– Kendala berupa pembatas
– Kendala berupa syarat
– Kendala berupa keharusan
Operation Research (skripsi dan tesis)
Operation Research adalah pendekatan ilmiah untuk
pengambilan keputusan yang melibatkan operasi dari sistem
organisasional. Karakteristik utama yang dimiliki oleh Penelitian
Operasional adalah (Puryani,2012):
Diterapkan pada persoalan yang berkaitan dengan bagaimana
mengatur dan mengkoordinasikan operasi atau kegiatan dalam suatu
organisasi.
Mengacu pada Broad View Point, yakni titik pandang organisasi,
sehingga memiliki konsistensi dengan organisasi secara
keseluruhan.
Menemukan solusi terbaik atau solusi optimal, oleh karenanya
search for optimality jadi tema penting dalam penelitian operasional.
Menurut Taha (1996), tahap-tahap utama yang harus dilalui
untuk melakukan studi OR adalah:
1. Definisi masalah
Dari sudut pandang riset operasi, hal ini menunjukkan tiga aspek
utama: (1) deskripsi tentang sasaran atau tujuan dari studi tersebut,
(2) identifikasi alternative keputusan dari system tersebut, dan (3)
pengenalan tentang keterbatasan, batasan, dan persyaratan system
tersebut.
2. Pengembangan model
Bergantung pada definisi masalah, harus memutuskan model yang
paling sesuai untuk mewakili system yang bersangkutan. Jika
model yang dihasilkan termasuk dalam salah satu model matematis
yang umum (misalnya, program linear), pemecahan yang
memudahkan dapat diperoleh dengan menggunakan teknik-teknik
matematis.
3. Pemecahan model
Dalam model-model matematis, hal ini dapat dicapai dengan
menggunakan teknik-teknik optimisasi yang didefinisikan dengan
baik dan model tersebut dikatakan menghasilkan sebuah
pemecahan optimal.
4. Pengujian keabsahan model
Sebuah model adalah absah jika, walaupun tidak secara pasti
mewakili system tersebut, dapat memberikan prediksi yang wajar
dari kinerja system tersebut. Satu metode yang umum untuk
menguji keabsahan sebuah model adalah menggunakan data masa
lalu untuk dibandingkan.
5. Implementasi hasil akhir
Implementasi melibatkan penerjemahan hasil ini menjadi petunjuk
operasi yang terinci dan disebarkan dalam bentuk yang mudah
dipahami kepada para individu yang akan mengatur dan
mengoperasikan system yang direkomendasikan tersebut.
Metode Peramalan (skripsi dan tesis)
Menurut Purnomo (2004), metode-metode yang dapat
digunakan untuk melakukan peramalan antara lain sebagai berikut:
1. Regresi Linear
Regresi Linear merupakan prosedur-prosedur statistical yang
paling banyak digunakan sebagai metode peramalan, karena
relatif lebih mudah dipahami dan hasil peramalan dengan metode
ini lebih akurat dalam berbagai situasi. Dalam metode ini, pola
hubungan antara suatu variabel yang mempengaruhinya dapat
dinyatakan dengan suatu garis lurus.
2. Moving Average
Metode moving average merupaka metode yang mudah
perhitungannya. Tujuan utama dari penggunaan metode ini
adalah untuk menghilangkan atau mengurangi acakan
(randomness) dalam deret waktu.
3. Exponential Smoothing
Metode ini pertama kali dikembangkan oleh para ahli penelitian
operasional pada akhir 1950. Sejak tahun 1960-an konsep
exponensial smoothing telah tumbuh menjadi metode praktis
dengan penggunaannya yang luas. Di dalam metode ini kita
berusaha menunjukkan adanya karakteristik dari smoothing
dengan menambahkan suatu faktor yang sering disebut dengan
smoothing constant dengan simbol alpha (α). Metode ini
memiliki rumus sebagai berikut:
Ft+1 = α (xt) + (1 – α) Ft
Dengan :
Xt = Nilai aktual terbaru
Ft = Peramalan terakhir
Ft+1 = peramalan untuk periode yang akan datang
α = Konstanta smoothing
Peramalan (skripsi dan tesis)
Kegiatan peramalan merupakan suatu fungsi bisnis yang
berusaha memperkirakan penjualan dan penggunaan produk sehingga
produk-produk tersebut dapat dibuat dalam jumlah yang tepat. Dengan
demikian, peramalan adalah perkiraan atau estimasi tingkat permintaan
suatu produk untuk periode yang akan datang (Purnomo,2004).
Secara garis besar terdapat tiga macam pengaruh yang dapat
mengakibatkan fluktuasi penjualan, yaitu sebagai berikut
(Purnomo,2004)
1. Pengaruh Trend Jangka Panjang
Pengaruh trend jangka panjang meunjukkan perkembangan
perusahaan dalam penjualannya. Perkembangan tersebut bisa positif
(Growth) maupun perkembangan negatif (Decline).
2. Pengaruh Musiman
Perubahan volume penjualan atau permintaan juga dapat
dipengaruhi oleh musim. Musiman merupakan permintaan tertentu
yang terjadi setiap periode tertentu. Pengaruh musim akan
menyebabkan adanya fluktuasi penjualan yang tertentu dalam satu
tahun dan membentuk pola penjualan musiman.
3. Pengaruh Cycles
Pengaruh cycles disebut juga pengaruh konjungtur. Pengaruh ini
merupakan gejala fluktuasi perekonomian jangka panjang. Pengaruh
ini mungkin yang paling sulit ditentukan bila rentangan waktu tidak
diketahui atau akibat siklus tidak dapat ditentukan.
Metode Linear Programming (skripsi dan tesis)
Menurut Siswanto (1987) Linear Programming adalah sebuah metode untuk
menentukan suatu putusan optimal yaitu suatu putusan yang memiliki nilai paling menguntungkan untuk fungsi tujuan di antara kemungkinan-kemungkinan putusan yang memenuhi kendala. Linear Programming adalah suatu persoalan untuk menentukan besarnya masing-masing nilai variabel, nilai fungsi tujuan yang linier menjadi optimum (maksimum atau minimum) dengan memperhatikan pembatasan-pembatasan yang ada yaitu pembatasan mengenai inputnya (Supratno,1983).
Ada dua fungsi penting yang harus diperhatikan dalam Linear Programming yaitu fungsi tujuan dan fungsi kendala. Fungsi tujuan hanya mempunyai kemungkinan bentuk maksimasi dan dapat juga minimasi. Fungsi kendala dapat berupa pembatas dan dapat juga berupa syarat. Fungsi kendala dapat berupa persamaan (=) atau pertidaksamaan (≤ atau ≥). Simbol ≤ akan selalu dijumpai pada fungsi kendala yang berua pembatas dan simbol ≥ akan selalu dijumpai pada fungsi kendala yang berupa syarat.
Menurut Supratno (1983), suatu persoalan Linear Programming apabila
memenuhi hal-hal berikut :
a. Tujuan (objective) yang akan dicapai harus dapat dinyatakan dalam bentuk
fungsi linier. Fungsi ini disebut fungsi tujuan (objective function).
b. Harus ada alternatif pemecahan. Pemecahan yang membuat nilai fungsi
tujuan optimum (laba yang maksimum, biaya yang minimum, dsb) yang
harus dipilih.
c. Sumber-sumber tersedia dalam jumlah yang terbatas (bahan terbatas, dsb).
Pembatasan-pembatasan harus dinyatakan di dalam pertidaksamaan yang
linier (linear inequality)
Hingga saat ini, Linear Programming telah dipergunakan di dalam penyelesaian berbagai masalah pada bidang usaha, pemerintah, industri, rumah sakit, perpustakaan dan pendidikan. Sebagai suatu teknik yang membantu dalam pembuatan putusan, pemrograman linier telah diterapkan pada bidang produksi, keuangan, pemasaran, penelitian, dan pengambangan dan personalia.
Menurut Siringoringo (2005), secara teknis, linearitas ditunjukan oleh adanya
empat sifat tambahan yang merupakan asumsi dasar, yaitu :
a. Sifat proporsionalitas merupakan asumsi aktivitas individual yang
dipertimbangkan secara bebas dari aktivitas lainnya. Sifat proporsionalitas
dipenuhi jika kontribusi setiap variabel pada fungsi tujuan atau penggunaan
sumber daya yang membatasi proporsional terhadap level nilai variabel.
b. Sifat additivitas mengasumsikan bahwa tidak ada bentuk perkalian silang
diantara berbagai aktivitas, sehingga tidak akan ditemukan bentuk perkalian
silang pada model. Sifat ini dipenuhi jika fungsi tujuan merupakan
penambahan langsung kontribusi masing-masing variabel keputusan untuk
fungsi pembatas (kendala). Sifat additivitas dipenuhi jika nilai kanan
merupakan total penggunaan masing-masing variabel keputusan.
c. Sifat divisibilitas berarti unit aktivitas dapat dibagi ke dalam sembarang level
fraksional, sehingga nilai variabel keputusan noninteger dimungkinkan.
d. Sifat kepastian menunjukan bahwa semua parameter model berupa
konstanta. Artinya koefisien fungsi tujuan maupun fungsi pembatas
merupakan suatu nilai pasti, bukan merupakan nilai dengan peluang
tertentu
Metode Diagram Keputusan (Decision Tree) (skripsi dan tesis)
Diagram Keputusan (Decision Tree) adalah suatu rangkaian kronologis tentang
keadaan apa yang mungkin terjadi untuk tiap alternatif keputusan
(Mangkusubroto & Trisnadi, 1983).
Dalam pembuatan pohon keputusan terdapat beberapa penuntun dan aturan
yang dapat digunakan sebagai pegangan dalam pembentukan dan penentuan
pilihan nilai diagram keputusan. Mangkusubroto dan Trisnadi (1983) menjelaskan
tahap penggambaran dan penentuan pilihan adalah sebagai berikut:
a. Tentukan alternatif keputusan awal atau alternatif tindakan.
b. Tentukan kejadian tak pasti yang melingkupi alternatif awal.
c. Tentukan keputusan atau alternatif lanjutan.
d. Tentukan kejadian tak pasti yang melingkupi alternatif lanjutan.
e. Gambarkan kejadian-kejadian dan keputusan-keputusan secara kronologis.
f. Menetapkan nilai kejadian, kemungkinan dan ekspektasi.
g. Menganalisis nilai secara bertahap.
Dalam menetapkan nilai kejadian ini berdasarkan nilai keuntungan dan kerugian
yang akan diterima pemilik dalam setiap rangkaian alternatif. Nilai kemungkinan
adalah besarnya nilai kemungkinan kemunculan dari setiap kejadian tak pasti.
Nilai ekpektasi merupakan harga rata-rata dari setiap kejadian. Nilai ekpetasi i
Kelebihan dan Kelemahan program linier (skripsi dan tesis)
a. Kelebihan dari program linier adalah ( Soekartawi,1992):
Di dalam penggunaannya, program linier mempunyai beberapa
kelebihan, diantaranya:
1) Mudah dilaksanakan, terutama jika menggunakan alat bantu
komputer
2) Dapat menggunakan banyak variabel, sehingga berbagai
kemungkinan untuk memperoleh pemanfaatan sumber daya yang
optimum dapat dicapai
3) Fungsi tujuan (objective function) dapat disesuaikan dengan
tujuan penelitian atau berdasarkan data yang tersedia.
b. Kelemahan dari program linier adalah ( Soekartawi,1992):
1) Bila alat bantu komputer tidak tersedia, maka program linier
yang menggunakan banyak variabel akan kesulitan dalam
analisisnya.
2) Nilai optimum dapat berupa pecahan, yang pada kasus tertentu
menghendaki harus bernilai bulat positif.
3) Penggunaan asumsi linieritas yang terkadang tidak sesuai dengan
kenyataan.
Asumsi-asumsi Dasar Program Linier (skripsi dan tesis)
Salah satu ciri khas model program linier ini ialah bahwa ia
didukung oleh lima macam asumsi yang menjadi tulang punggung model
tersebut. Asumsi-asumsi tersebut adalah sebagai berikut:
a. Linearitas
Asumsi ini menginginkan agar perbandingan antara input yang
satu dengan input lainnya, atau untuk suatu input dengan output
besarnya tetap dan terlepas (tidak tergantung) pada tingkat produksi.
Jika fungsi tujuan, cjxj, bersifat nonlinear, maka teknik program linier
ini tidak dapat dipakai.
b. Proporsionalitas
Asumsi ini menyatakan bahwa jika peubah pengambilan
keputusan, xj, berubah maka dampak perubahannya akan menyebar
dalam proporsi yang sama terhadap fungsi tujuan, cjxj, dan juga pada
kendalanya, aijxj. Misalnya, jika kita naikkan nilai xj dua kali, maka
secara proporsional (seimbang dan serasi) nilai-nilai aijxj-nya juga akan
menjadi dua kali lipat. Implikasi asumsi ini ialah bahwa dalam model
program linier yang bersangkutan tidak berlaku hukum kenaikan yang
semakin menurun.
c. Aditivitas
Asumsi ini menyatakan bahwa nilai parameter suatu kriteria
optimasi (koefisien peubah pengambilan keputusan dalam fungsi
tujuan) merupakan jumlah dari nilai individu-individu cj dalam model
program linier tersebut. Dampak total terhadap kendala ke-i
merupakan jumlah dampak individu terhadap peubah pengambilan
keputusan xj.
d. Divisibilitas
Asumsi ini menyatakan bahwa peubah-peubah pengambilan
keputusan xj, jika diperlukan dapat dibagi ke dalam pecahan-pecahan,
yaitu bahwa nilai-nilai xj tidak perlu integer (hanya 0 dan 1 atau
bilangan bulat), tapi boleh noninteger (missal ½; 0,58; 38,987, dan
sebagainya).
e. Deterministik
Asumsi ini menghendaki agar semua parameter dalam model
program linier (yaitu nilai-nilai cj, aij, dan bi) tetap dan diketahui atau
di tentukan secara pasti (Nasendi, 1985).
4. Macam-macam solusi program linier
Setelah persoalan program linier diidentifikasikan variabel
keputusan, fungsi tujuan, dan pembatasannya yang diformulasikan ke
dalam bentuk matematika, maka persoalan tersebut dapat dipecahkan
menggunakan beberapa metode seperti metode grafik, metode substitusi,
dan metode simpleks.
a. Metode Grafik
Pemecahan persoalan program linier menggunakan metode grafik
terdiri dari dua fase yaitu (Ruminta, 2009):
1) Menentukan ruang/daerah penyelesaian (solusi) yang feasible
yaitu menemukan nilai variabel keputusan di mana semua
pembatasan bertemu.
2) Menentukan solusi optimal dari semua titik di ruang/ daerah
feasible
b. Metode Substitusi
Penyelesaian program linier dengan metode substitusi
mempunyai beberapa tahapan yaitu (Ruminta, 2009):
1) Mengubah ketidaksamaan pembatasan menjadi persamaan
pembatasan dengan cara menambahkan variabel slack (Surplus)
untuk persoalan maksimum (minimum).
2) Tentukan seluruh pemecahan dasar dari persamaan pembatasan dan
tentukan pemecahan yang memenuhi semua syarat pembatasan
(solusi feasible).
3) Tentukan salah satu dari solusi feasible tersebut yang memenuhi
syarat fungsi tujuan atau solusi optimum.
c. Metode simpleks
Metode simpleks adalah suatu teknik penyelesaian program
linier secara iterasi. Metode simpleks mencari suatu penyelesaian dasar
feasible ke penyelesaian dasar feasible yang lainnya dilakukan
berulang-ulang sehingga akhirnya tercapi suatu penyelesaian optimum
(Ruminta, 2009).
Pada metode simpleks persoalan program linier selalu diubah
menjadi persoalan program linier standar, dimana setiap
ketidaksamaan pembatasan diekspresikan dalam bentuk persamaan
pembatasan dengan menambah variabel slack atau surplus.
Menurut Siringoringo (2005) ada beberapa istilah yang sangat
sering digunakan dalam metode simpleks, diantaranya :
1) Iterasi adalah tahapan perhitungan dimana nilai dalam perhitungan
itu tergantung dari nilai tabel sebelumnya.
2) Variabel non basis adalah variabel yang nilainya diatur menjadi
nol pada sembarang iterasi.
3) Variabel basis merupakan variabel yang nilainya bukan nol pada
sembarang iterasi. Pada solusi awal, variabel basis merupakan
variabel slack (jika fungsi kendala merupakan pertidaksamaan ≤ )
atau variabel buatan (jika fungsi kendala menggunakan
pertidaksamaan ≥ atau =). Secara umum, jumlah variabel basis
selalu sama dengan jumlah fungsi pembatas (tanpa fungsi non
negatif).
4) Solusi atau nilai kanan merupakan nilai sumber daya pembatas
yang masih tersedia. Pada solusi awal, nilai kanan atau solusi
sama dengan jumlah sumber daya pembatas awal yang ada,
karena aktivitas belum dilaksanakan.
Model Optimalisasi Kebutuhan…, Elia Zubaedah, FKIP UMP, 2013
16
5) Variabel slack adalah variabel yang ditambahkan ke model
matematik kendala untuk mengkonversikan pertidaksamaan ≤
menjadi persamaan (=). Penambahan variabel ini terjadi pada
tahap inisialisasi. Pada solusi awal, variabel slack akan berfungsi
sebagai variabel basis.
6) Variabel surplus adalah variabel yang dikurangkan dari model
matematik kendala untuk mengkonversikan pertidaksamaan ≥
menjadi persamaan (=). Penambahan ini terjadi pada tahap
inisialisasi. Pada solusi awal, variabel surplus tidak dapat
berfungsi sebagai variabel basis.
7) Variabel buatan adalah variabel yang ditambahkan ke model
matematik kendala dengan bentuk ≥ atau = untuk difungsikan
sebagai variabel basis awal. Penambahan variabel ini terjadi pada
tahap inisialisasi.
8) Kolom pivot (kolom kerja) adalah kolom yang memuat variabel
masuk. Koefisien pada kolom ini akan menjadi pembagi nilai
kanan untuk menentukan baris pivot (baris kerja).
9) Baris pivot (baris kerja) adalah salah satu baris dari antara
variabel basis yang memuat variabel keluar.
10) Elemen pivot (elemen kerja) adalah elemen yang terletak pada
perpotongan kolom dan baris pivot. Elemen pivot akan menjadi
dasar perhitungan untuk tabel simpleks berikutnya.
11) Variabel masuk adalah variabel yang terpilih untuk menjadi
variabel basis pada iterasi berikutnya. Variabel masuk dipilih satu
dari antara variabel non basis pada setiap iterasi. Variabel ini pada
iterasi berikutnya akan bernilai positif.
12) Variabel keluar adalah variabel yang keluar dari variabel basis
pada iterasi berikutnya dan digantikan oleh variabel masuk.
Variabel keluar dipilih satu dari antara variabel basis pada setiap
iterasi. Variabel ini pada iterasi berikutnya akan bernilai nol.
Sebelum melakukan perhitungan iteratif untuk menentukan
solusi optimal, pertama sekali bentuk umum pemrograman linier
dirubah ke dalam bentuk baku terlebih dahulu. Bentuk baku dalam
metode simpleks tidak hanya mengubah persamaan kendala ke dalam
bentuk sama dengan, tetapi setiap fungsi kendala harus diwakili oleh
satu variabel basis awal. Variabel basis awal menunjukkan status
sumber daya pada kondisi sebelum ada aktivitas yang dilakukan.
Dalam kasus minimalisasi yang berfungsi sebagai variabel basis adalah
variabel buatan / artificial variable. Perumusannya dalam fungsi tujuan
memiliki koefisien sebesar +M. Pendekatan ini disebut juga sebagai ”
metode M besar ”. Nilai koefisien peubah artifisial itu sendiri adalah
sebenarnya tak terhingga.
Dalam perhitungan iteratif, kita akan bekerja menggunakan
tabel. Bentuk baku yang sudah diperoleh, harus dibuat ke dalam
bentuk tabel.
Langkah-langkah penyelesaian adalah sebagai berikut :
a. Merubah model program linier menjadi model persamaan linier.
b. Menyusun tabel simpleks awal.
c. Menghitung nilai Zj pada setiap kolom variabel.
d. Menghitung nilai (Cj-Zj) pada setiap kolom variabel.
e. Periksa nilai-nilai (Cj-Zj), jika (Cj-Zj) ≤ 0 (untuk tujuan
memaksimumkan) maka ke langkah (l) atau jika (Cj-Zj) ≥ 0 (untuk
tujuan meminimumkan) maka ke langkah (l).
f. Tentukan kolom kunci berdasarkan nilai (Cj-Zj). Kolom kunci
terletak pada kolom variabel yang nilai (Cj-Zj) positif terbesar jika
tujuannya memaksimumkan, sebaliknya kolom kunci terletak pada
kolom variabel yang nilai (Cj-Zj) negatif terbesar jika tujuannya
meminimumkan.
g. Tentukan baris kunci berdasarkan nilai (bi / akk) positif terkecil.
h. Tentukan angka kunci (ak), yaitu angka yang terletak pada kolom
kunci dan baris kunci.
i. Ganti variabel yang terletak pada baris kunci dengan variabel yang
terletak pada kolom kunci.
j. Lakukan transformasi setiap baris yang dimulai dengan baris kunci
dengan rumus transformasi sebagai berikut:
Bk baru = (Bk lama) / ak
Bi baru = Bi – ai,kk * Bk baru
k. Kembali ke langkah (c)
l. Solusi optimal diperoleh, dimana nilai variabel basis untuk masingmasing
baris terletak pada kolom bi.
Pengertian Program Linier (skripsi dan tesis)
Program Linier (PL) yang dalam bahasa Inggris disebut linear
programming, adalah salah satu teknik riset operasi yang memakai model
matematika. Tujuannya adalah untuk mencari, memilih, dan menentukan
alternatif yang terbaik dari antara sekian alternatif layak yang tersedia.
Dikatakan linier karena peubah-peubah yang membentuk model PL
dianggap linier (Nasendi, 1985).
Program linier pada hakikatnya merupakan suatu teknik
perencanaan yang bersifat analitis yang analisis-analisisnya memakai
model matematika, dengan tujuan menemukan beberapa kombinasi
alternatif pemecahan masalah, kemudian dipilih mana yang terbaik di
antaranya dalam rangka menyusun strategi dan langkah-langkah kebijakan
lebih lanjut tentang alokasi sumber daya dan dana yang terbatas guna
mencapai tujuan atau sasaran yang diinginkan secara optimal.
Penekanannya di sini adalah pada alokasi optimal atau kombinasi
optimum, artinya suatu langkah kebijakan yang pertimbangannya telah
dipertimbangkan dari segala segi untung dan rugi secara baik, seimbang
dan serasi. Alokasi optimal tersebut tidak lain adalah memaksimumkan
atau meminimumkan fungsi tujuan yang memenuhi persyaratanpersyaratan
yang dikehendaki oleh syarat-ikatan (kendala) dalam bentuk
ketidaksamaan linier.
Dalam masalah program linier senantiasa dijumpai adanya
persyaratan atau konstrain yang ditimbulkan oleh adanya fasilitas. Fasilitas
yang terbatas dapat berupa kapasitas mesin yang terbatas, persediaan
bahan baku yang terbatas, jumlah tenaga yang terbatas dan sebagainya.
Agar dapat menyusun dan merumuskan suatu persoalan atau permasalahan
yang dihadapi ke dalam model program linier, maka dimintakan lima
syarat yang harus dipenuhi sebagai berikut ini (Nasendi, 1985):
a. Tujuan
Apa yang menjadi tujuan permasalahan yang dihadapi yang ingin
dipecahkan dan dicari jalan keluarnya. Tujuan ini harus jelas dan tegas
yang disebut fungsi tujuan. Fungsi tujuan tersebut dapat berupa
dampak positif, manfaat-manfaat, keuntungan-keuntungan, dan
kebaikan-kebaikan yang akan dimaksimumkan, atau dampak negatif,
kerugian-kerugian, risiko-risiko, biaya-biaya, jarak, waktu, dan
sebagainya yang akan diminimumkan.
b. Alternatif perbandingan
Harus ada sesuatu atau berbagai alternatif yang ingin diperbandingkan,
misalnya antara kombinasi waktu tercepat dan biaya tertinggi dengan
waktu terlambat dan biaya terendah, atau antara kebijakan A dengan B,
atau antara proyeksi permintaan tinggi dengan rendah, dan seterusnya.
c. Sumber daya
Sumber daya yang dianalisis harus berada dalam keadaan yang
terbatas. Misalnya keterbatasan waktu, keterbatasan biaya,
keterbatasan tenaga, keterbatasan luas tanah, keterbatasan ruangan, dan
lain-lain. Keterbatasan dalam sumber daya tersebut dinamakan sebagai
kendala atau syarat-ikatan.
d. Perumusan kuantitatif
Fungsi tujuan dan kendala tersebut harus dapat dirumuskan secara
kuantitatif dalam apa yang disebut model matematika.
e. Keterkaitan peubah
Peubah-peubah yang membentuk fungsi tujuan dan kendala tersebut
harus memiliki hubungan fungsional atau hubungan keterkaitan.
Hubungan keterkaitan tersebut dapat diartikan sebagai hubungan yang
saling mempengaruhi, hubungan interaksi, independensi, timbal balik,
saling menunjang, dan sebagainya
Model Matematika (skripsi dan tesis)
Model adalah representasi suatu realitas dari seorang pemodel atau
dengan kata lain model adalah jembatan antara dunia nyata dengan dunia
berpikir untuk memecahkan masalah. Menurut Pagalay (2009), proses
penjabaran atau merepresentasikan disebut modeling atau pemodelan yang
tidak lain merupakan proses berpikir melalui sekuen logis.
Tahap-tahap pemodelan matematika yaitu:
a. Identifikasi masalah
Identifikasi masalah dibangun dari berbagai pertanyaan untuk
membangun suatu model.
b. Penyederhanaan masalah
Dalam tahap ini dibangun asumsi-asumsi untuk penyederhanaan
realitas yang kompleks. Oleh karena itu setiap penyederhanaan
memerlukan asumsi, sehingga ruang lingkup model berada dalam koridor
permasalahan yang akan dicari solusi atau jawabannya.
c. Penyelesaian dan analisis model matematika
Inti tahap ini adalah mencari solusi yang sesuai untuk menjawab
pertanyaan yang dibangun pada tahap identifikasi.
d. Pengintrepetasian hasil ke situasi nyata
Tahap selanjutnya adalah melakukan intepretasi atas hasil yang
dicapai dalam tahap analisis. Pengintrepetasian juga penting dilakukan
untuk mengetahui apakah hasil analisis yang dilakukan oleh komputer
ataupun alat pemecah model lainnya (solver).
Bentuk Umum Linear Programming (skripsi dan tesis)
LPP umum dapat digambarkan sebagai berikut :
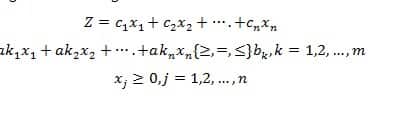
Diberikan satu set m – linear kesenjangan atau persamaan dalam n – variabel , kita ingin mencari nilai-nilai non-negatif dari variabel-variabel yang akan memenuhi kendala dan mengoptimalkan ( memaksimalkan atau meminimalkan ) fungsi linier dari variabel-variabel ( fungsi tujuan ).
Secara matematis , kami memiliki kesenjangan m – linear dengan n – variabel (m dapat lebih besar dari , kurang dari atau sama dengan n ) dari bentuk tersebut. Untuk setiap kendala, hanya satu dari tanda-tanda ini (≥, = , ≤) digunakan, tapi dapat bervariasi dari satu kendala kepada kendala yang lain untuk mencari nilai variabel Xj memenuhi ( 3.1 ) dan yang memaksimalkan atau meminimalkan fungsi linea.
LPP dalam Bentuk Canonical
secara umum ≤ kendala akan dikaitkan dengan maksimalisasi LPP dan ≥ kendala dengan minimalisasi LPP.
Maksimalisasi :
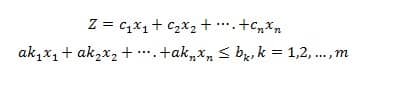
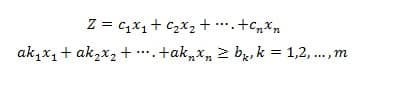
Catatan: ketika tidak ada disebutkan tentang kenegativan variabel, maka terbatas dalam tanda atau diabaikan.
Langkah-langkah perumusan masalah pemrograman linier ( LPP) (skripsi dan tesis)
Langkah-langkah berikut yang terlibat dalam perumusan linear programming probel ( LPP).
- Langkah 1 : mengidentifikasi variabel keputusan masalah.
- Langkah 2 : membangun fungsi tujuan sebagai kombinasi lonear dari variabel keputusan ,
- Langkah 3 mengidentifikasi kendala dari masalah seperti sumber daya , limitions , antar – hubungan antara variabel , dll Merumuskan kendala ini sebagai persamaan linear atau inequations dalam hal variabel keputusan non negatif.
Dengan demikian , LPP adalah kumpulan fungsi tujuan , himpunan kendala dan set non -negatif kendala.
Fungsi Linear Programming (skripsi dan tesis)
Dalam model linear programming dikenal 2 macam fungsi :
1. Fungsi Tujuan (objective Function)
Fungsi tujuan ialah fungsi yang menggambarkan suatu tujuan ataupun sasaran ataujuga target didalam suatu permasalahan linear programming yang berkaitan dengan suatu peraturan dengan secara optimal sumber daya(resource) untuk memperoleh suatu keuntungan yang maksimal.
2. Fungsi Batasan (Constraint Function)
Fungsi ialah suatu bentuk penyajian dengan secara sistematis batasan-batasan suatu kapasitas yang tersedia akan dapat dialokasikan secara optimal. Masalah linear programming tersebut dapat dinyatakan ialah sebagai proses optimisasi suatu fungsi tujuan didalam bentuk Memaksimumkan ataupun meminimumkan.
Model Linear Programing (skripsi dan tesis)
Ciri khas model linear programming ialah bahwa linear programming tersebut didukung oleh macam-macam asumsi yang menjadikan sebagai tulang punggung model tersebut. Asumsi tersebut antara lain ialah sebagai berikut
-
Propotionality
Pada Asumsi ini ialah bahwa naik turunnya nilai z dan juga penggunaan faktor-faktor produksi yang tersedia akan dapat berubah secara sebanding atau sejajar (proposional) pada perubahan tingkat kegiatan.
-
Additivity
Pada Asumsi ini ialah bahwa nilai tujuan pada tiap kegiatan tidak saling mempengaruhi satu sama lain, atau dalam linear programming tersebut dianggap bahwa suatu kenaikan nilai tujuan yang diakibatkan oleh kenaikan suatu kegiatan(proses) dapat ditumbuhkan dengan tidak harus mempengaruhi nilai Z yang diperoleh dari kegiatan lain.
-
Divisibility
Pada Asumsi ini menyatakan bahwa suatu keluaran (output) yang dihasilkan oleh suatu kegiatan(proses) dapat berupa suatu bilangan pecahan, demikian juga dengan nilai Z yang dihasilkan.
-
Deterministic (certainty)
Pada Asumsi ini menyatakan bahwa semua parameter yang terdapat didalam model linear programming (aij, bj, cj ) tersebut dapat diperkirakan dengan pasti walaupun jarang digunakan tepat.
Pengertian Linear Programing Menurut Para Ahli (skripsi dan tesis)
Banyak Sekali Definisi Menurut Para Ahli , antara lain ialah sebagai berikut :
-
T. Hani Handoko (1999, p379) :
Linear Programing ialah suatu metode analitik paling terkenal dan yang merupakan suatu bagian pada kelompok teknik-teknik yang disebut dengan programisasi matematik.
-
Sofjan Assauri (1999, p9) :
pengertian linear Programing ialah suatu teknik perencanaan yang dengan menggunakan model matematika dengan tujuan untuk menemukan kombinasi-kombinasi produk yang terbaik didalam menyusun suatu alokasi sumber daya yang terbatas guna untuk mencapai tujuan yang digunakan dengan secara optimal.
-
Zainal Mustafa, EQ, dan juga Ali Parkhan (2000, p43)
Linear Programing ialah suatu cara yang lazim digunakan dalam pemecahan suatu masalah pengalokasian sumber-sumber yang terbatas dengan secara optimal.
-
Zulian Yamit (1996, p14) :
Linear programming ialah metode ataupun teknik matematis yang digunakan untuk dapat membantu manajer dalam pengambilan keputusan. Ciri khusus dalam penggunaan metode matematis ini ialah berusaha untuk mendapatkan maksimisasi atau juga minimisasi.
Pengertian Linear Programming (skripsi dan tesis)
Secara umum Linear Programming ialah salah satu teknik dari Riset Operasi untuk memecahkan persoalan optimasi (maksimasi atau minimasi) dengan menggunakan persamaan dan ketidaksamaan linear dalam rangka untuk mencari pemecahan yang optimum dengan memperhatikan pembatasan-pembatasan yang ada. Dalam keadaan sumber yang terbatas harus dicapai suatu hasil yang optimum dengan perkataan lain bagaimana caranya agar dengan masukan input yang terbatas dapat menghasilkan keluaran output berupa produksi barang atau jasa yang optimum. Salah satu metoda analisis dalam teknik operasional riset untuk menyelesaikan persoalan pengalokasian sumber-sumber terbatas adalah menggunakan metoda program linear. Linear programming akan memberikan banyak sekali hasil pemecahan persoalan, sebagai alternatif pengambilan tindakan, akan tetapi hanya ada satu yang optimum (maksimum atau minimum). Memilih keputusan berarti memilh alternatif, tapi yang terpenting adalah pengambilan alternatif terbaik( the best alternative), Johannes Suprapto (1987).
Menurut Hari Purnomo(2004) Pokok pikiran utama dalam menggunakan program linier adalah merumuskan masalah dengan menggunakan sejumlah informasi yang tersedia, kemudian menerjemahkan masalah tersebut dalam bentuk model matematika. Sifat linear mempunyai arti bahwa seluruh fungsi dalam model ini merupakan fungsi yang linear
Realibilitas (skripsi dan tesis)
Uji reliabilitas adalah pengukuran untuk suatu gejala. Semakin tinggi realibilitas suatu alat ukur, maka semakin stabil alat tersebut untuk digunakan. Tingkat realibilitas suatu konstruk atau variabel penelitian dapat dilihat dari hasil statistik Cronbach Alpha (α) Suatu variabel dikatakan reliable jika memberikan nilai cronbach alpha > 0,60. Semakin nilai alphanya mendekati 21 satu maka nilai realibilitas datanya semakin terpercaya.Dengan kata lain, realibilitas menunjukkan konsistensi suatu alat pengukur di dalam pengukur gejala yang sama. Uji realibilitas dilakukan dengan rumus Croansbach’s Alpha
Uji Validitas (skripsi dan tesis)
Pengujian validitas data digunakan untuk mengukur sah atau valid tidaknya suatu kuesioner. Suatu kuesioner dianggap valid jika pertanyaan pada kuesioner mampu mengungkapkan sesuatu yang diukur oleh kuesioner tersebut. Pengujian validitas dilakukan dengan bantuan program SPSS for windows. Pengambilan keputusan berdasarkan nilai p value atau nilai signifikasi kurang dari 0,05, maka item pertanyaan tersebut dinyatakan valid dan sebaliknya jika nilai p value atau signifikasi sama dengan atau lebih dari 20 0,05 dinilai tidak valid. Cara analisisnya dengan cara menghitung koefisien korelasi antara masing-masing nilai pada nomor pertanyaan dengan nilai total dari nomor pertanyaan tersebut. Selanjutnya koefisien korelasi yang diperoleh r masih harus diuji signifikansinya bisa menggunakan uji t atau membandingkannya dengan r tabel.Bila t hitung > dari t tabel atau r hitung >dari r tabel, maka nomor pertanyaan tersebut valid. Bila menggunakan program komputer, asalkan r yang diperoleh diikuti harga p< 0,05 berarti nomor pertanyaan itu valid
Ekstraksi Faktor (skripsi dan tesis)
Ekstraksi faktor yang bertujuan untuk mengetahui jumlah faktor yang terbentuk dari data yang ada.Pada tahap ini, akan dilakukan proses inti dari analisis faktor, yaitu melakukan ekstraksi terhadap sekumpulan variabel yang 17 adaKMO>0,5, sehingga terbentuk satu atau lebih faktor.Metode ekstrasi yang digunakan adalah Analisis Komponen Utama (Principal Components Analysis). Analisis komponen utama merupakan teknik statistik yang digunakan untuk menjelaskan struktur variansi-kovariansi dari sekumpulan variabel melalui beberapa variabel baru dimana variabel baru ini saling bebas, dan merupakan kombinasi linier dari variabel asal. Selanjutnya, variabel baru ini dinamakan komponen utama. Secara umum tujuan dari analisis komponen utama adalah mereduksi dimensi data sehingga lebih muda untuk menginterpretasikan data-data tersebut. Analisis komponen utama bertujuan untuk menyederhanakan variabel yang diamati dengan cara menyusutkan dimensinya. Hal ini dilakukan dengan menghilangkan korelasi variabel melalui transformasi variabel asal ke variabel baru yang tidak berkorelasi.Variabel baru (𝑌)disebut komponen utama yang merupakan hasil transformasi dari variabel asal X yang modelnya dalam bentuk catatan matriks
Kegunaan Analisis Faktor (skripsi dan tesis)
Analisis faktor mempunyai beberapa kegunaan adalah sebagai berikut : a) Untuk mengidentifikasi underlying dimensions (factors) yang dapat menjelaskan korelasi sekumpulan variabel.Untuk mengidentifikasi variabel baru, yang dapat digunakan untuk analisis l lainnya c) Untuk mengedintifikasi satu atau beberapa variabel dari variabel yang banyak jumlahnya. d) Mengkonfirmasi kontruksi suatu variabel latin
Analisis faktor (skripsi dan tesis)
Analisis faktor merupakan salah satu metode statistika multivariate yang digunakan untuk menemukan beberapa faktor yang mendasari dan mampu menjelaskan hubungan atau korelasi antara berbagai indikator independen yang diobservasi . Metode analisis faktor pertama kali digunakan oleh Charles Spearman untuk memecahkan persoalan psikologi dalam tulisannya pada American Journal of Psychology pada tahun 1904 mengenai dan pengukuran intelektual.Analisis faktor menganalisis sejumlah variabel dari suatu pengukuran atau pengamatan yang dititikberatkan pada teori dan kenyataan yang sebenarnya dan menganalisis interkolerasi (hubungan) antara variabel untuk menetapkan apakah variasi-variasi yang tampak dalam variabel-variabel tersebut berdasarkan sejumlah faktor dasar yang jumlahnya lebih sedikit dari jumlah variasi yang ada variabel. Selain itu analisis faktor merupakan metode yang dapat digunakan untuk mereduksi data yaitu suatu proses untuk meringkas sejumlah variabel independen yang saling berkorelasi untuk dikelompokan menjadi sebuah variabel baru yang diberi nama faktor. Prinsip dasar analisis faktor adalah mengekstrasi sejumlah faktor (common factor) dari gugusan variabel asal𝑋1, 𝑋2, 𝑋3, …., 𝑋𝑝, sehingga banyaknya faktor lebih sedikit dari banyaknya variabel asal x yang tersimpan dalam sejumlah faktor
Faktor Rotasi (Rotated Factor Loading) (skripsi dan tesis)
Faktor rotasi menunjukkan korelasi antara variabel yang diperkirakan dari matriks faktor.Dalam rotasi faktor dikenal dua jenis rotasi, yaitu rotasi orthogonal dan rotasi oblique. Dalam rotasi orthogonal variabel – variabel diekstraksi sedemikian rupa, sehingga variabel – variabel tersebut independent satu sama lain, dengan melakukan rotasi tegak lurus. Sedangkan pada oblique tidak perlu melakukan rotasi tegak lurus.(Santoso,2010) Metode rotasi dengan orthogonal yang banyak dipergunakan yaitu varimaxrotation.Prosedur ini digunakan untuk meminumkan (membuat sedikit mungkin) banyaknya variabel dengan muatan tinggi (high loading) pada satu faktor. (Supranto,2010)
Faktor Rotasi (Rotated Factor Loading) (skripsi dan tesis)
Faktor rotasi menunjukkan korelasi antara variabel yang diperkirakan dari matriks faktor.Dalam rotasi faktor dikenal dua jenis rotasi, yaitu rotasi orthogonal dan rotasi oblique. Dalam rotasi orthogonal variabel – variabel diekstraksi sedemikian rupa, sehingga variabel – variabel tersebut independent satu sama lain, dengan melakukan rotasi tegak lurus. Sedangkan pada oblique tidak perlu melakukan rotasi tegak lurus.(Santoso,2010) Metode rotasi dengan orthogonal yang banyak dipergunakan yaitu varimaxrotation.Prosedur ini digunakan untuk meminumkan (membuat sedikit mungkin) banyaknya variabel dengan muatan tinggi (high loading) pada satu faktor. (Supranto,2010)
Asumsi Pada Analisis Faktor (skripsi dan tesis)
Karena prinsip utama analisis faktor adalah korelasi, maka asumsi – asumsi terkait dengan korelasi akan digunakan, yakni : (Santoso,2010) a. Besar korelasi atau korelasi antar variabel independen harus cukup kuat, misalkan diatas 0,5 b. Besar korelasi parsial, korelasi antara dua variabel dengan menganggap tetap variabel yang lain, justru harus kecil c. Pengujian seluruh matriks korelasi (korelasi antar variabel) yang diukur dengan besaran Bartlett Test Of Sphericity atau Measure Sampling Adequacy (MSA). Pengujian ini mengharuskan adanya korelasi yang signifikan di antara paling sedikit beberapa variabel d. Pada beberapa kasus, asumsi normalitas dari variabel – variabel atau faktor yang terjadi sebaiknya terpenuhi.
Tujuan Analisis Faktor (Skripsi dan tesis)
Pada dasarnya tujuan analisis faktor adalah (Santoso,2010) a. Data summarizationyakni mengidenfikasi adanya hubungan antara variabel dengan melakukan uji korelasi. b. Data reduction yakni setelah melakukan korelasi, dilakukan proses membuat sebuah variabel set baru yang dinamakan faktor untuk menggantikan sejumlah variabel tertentu.
Kegunaan Analisis Faktor (skripsi dan tesis)
Analisis faktor dipergunakan didalam situasi sebagai berikut : (Supranto,2010) a. Mengenali atau mengidentifikasi dimensi yang mendasari (underlying dimensions) atau faktor, yang menjelaskan korelasi antara suatu set variabel. b. Mengenali atau mengidentifikasi suatu set variabel baru yang tidak berkorelasi (independent) yang lebih sedikit jumlahnya untuk menggantikan suatu set variabel yang saling berkorelasi didalam analisis multivariat selanjutnya, misalnya analisis regresi berganda dan analisis diskriminan. c. Mengenali atau mengidentifikasi suatu set yang penting dari suatu set variabel yang lebih banyak jumlahnya untuk dipergunakan didalam analisis multivariat selanjutnya.
Analisis Faktor (skripsi dan tesis)
Proses analisis faktor mencoba menemukan hubungan (interrelationship) antara sejumlah variabel – variabel yang saling independen satu dengan yang lain, sehingga bisa dibuat satu atau beberapa kumpulan variabel yang lebih sedikit dari jumlah variabel awal. (Santoso, 2010) Analisis faktor didasarkan pada sebuah model dimana vektor hasil pengamatan dipartisi ke dalam suatu bagian sistematik yang tak teramati dan suatu bagian error yang tak teramati.Komponen dari vektor error dianggap bebas (independent) dari komponen vektor sistematik, dimana bagian sistematik merupakan kombinasi linier dari variabel faktor yang jumlahnya relatif lebih sedikit.Analisis faktor memisahkan pengaruh faktor yang menjadi perhatian dasar dari error (Anderson.T.W, 1984). Salah satu kelebihan dari analisis faktor adalah ketika bentuk persamaan tidak cocok dengan data, perkiraan korelasi antar faktor dengan variabel jelas mencerminkan kegagalan. Dalam sebuah kasus, ada dua permasalahan dalam perkiraan yaitu (1) tidak jelas banyaknnya faktor yang dibentuk dan (2) tidak jelas nama faktor yang di tentukan. Dalam prosedur statistik lain, kegagalan asumsi tidak mengakibatkan konsekuensi yang jelas seperti dalam perkiraan korelasi. Namun hal ini menjadi asumsi dasar analisis faktor. (Rencher A.C., 2002)
Teknik umum dalam analisis faktor adalah metode principal component analysis, yaitu metode yang digunakan untuk memperkirakan korelasi antara faktor yang akan dibentuk terhadap variabel.(Rencher A.C.,2002) Pada metode principal analysis factor bertujuan untuk mencari korelasi pada faktor terhadap variabel – variabel secara linier serta mengurangi (perkiraan) dimensi dari ruang vektor yang menggandung variabel – variabel dari satu set variabel acak yang intercorrelated. Dalam metode ini variabel yang diamati bergantung pada jumlah faktor yang lebih sedikit yang dapat dijelaskan dari varians atau kovarians yang sistematis atau benar dari penelitianuntuk memperkirakandan mengidentifikasi variabel yang nyata (tapi tidak teramati) yang berpengaruh pada variabel acak (Basilevsky .A., 1994)
Analisis Faktor (skripsi dan tesis)
Menurut Hair, et al. (1995) analisis faktor adalah sebuah nama umum yang diberikan kepada sebuah kelas dari metode statistika multivariat yang tujuan utamanya adalah menentukan struktur yang mendasari keterkaitan (korelasi) antara sejumlah variabel. P Faktor merupakan variabel baru yang bersifat tidak bisa diukur atau tidak dapat diamati. Sedangkan X adalah variabel yang dapat diukur atau diamati. Faktor dalam analisis faktor dibentuk untuk memaksimalkan penjelasan dari sekelompok variabel, bukan digunakan untuk memprediksi suatu variabel tidak bebas. Dalam analisis faktor variabel-variabel dikelompokkan berdasarkan korelasinya, yaitu variabel yang mempunyai korelasi tinggi akan berada dalam kelompok tertentu membentuk suatu faktor dan variabel-variabel yang mempunyai korelasi rendah akan membentuk faktor lain. Secara umum dapat dikatakan bahwa analisis ini bertujuan untuk menganalisis hubungan sejumlah besar variabel dengan menentukan satu kelompok dimensi umum yang disebut faktor (Hair, et al. 1995). Dalam melakukan analisis faktor keputusan pertama yang harus diambil oleh peneliti adalah menganalisis apakah data yang ada cukup memenuhi syarat di dalam analisis faktor. Langkah ini dilakukan dengan mencari matriks korelasi 6 antara indikator-indikator yang diobservasi. Metode Kaiser-Mayer Olkin (KMO) paling banyak digunakan untuk melihat syarat kecukupan data untuk analisis faktor. Metode ini mengukur kecukupan sampel secara menyeluruh dan mengukur kecukupan sampel untuk setiap indikator
Jenis Dalam Regresi Logistik (skripsi dan tesis)
Sebagaimana metode regresi biasa, Regresi Logistik dapat dibedakan menjadi 2, yaitu:
1. Binary Logistic Regression (Regresi Logistik Biner). Regresi Logistik biner digunakan ketika hanya ada 2 kemungkinan variabel respon (Y), misal membeli dan tidak membeli.
2. Multinomial Logistic Regression (Regresi Logistik Multinomial). Regresi Logistik Multinomial digunakan ketika pada variabel respon (Y) terdapat lebih dari 2 kategorisasi
Asumsi Dalam Regresi Logistik (skripsi dan tesis)
Asumsi yang harus dipenuhi dalam Regresi Logistik antara lain: 1. Regresi logistik tidak membutuhkan hubungan linier antara variabel independen dengan variabel dependen. 2. Variabel independen tidak memerlukan asumsi multivariate normality. 3. Asumsi homokedastisitas tidak diperlukan 4. Variabel bebas tidak perlu diubah ke dalam bentuk metrik (interval atau skala ratio). 5. Variabel dependen harus bersifat dikotomi (2 kategori, misal: tinggi dan rendah atau baik dan buruk) 6. Variabel independen tidak harus memiliki keragaman yang sama antar kelompok variabel 7. Kategori dalam variabel independen harus terpisah satu sama lain atau bersifat eksklusif 8. Sampel yang diperlukan dalam jumlah relatif besar, minimum dibutuhkan hingga 50 sampel data untuk sebuah variabel prediktor (independen). 9. Regresi logistik dapat menyeleksi hubungan karena menggunakan pendekatan non linier log transformasi untuk memprediksi odds ratio. Odd dalam regresi logistik sering dinyatakan sebagai probabilitas.
Pengertian regresi Logistik (skripsi dan tesis)
Dalam sebuah penelitian biasanya kita memodelkan hubungan antar 2 variabel, yaiitu variabel X (independent) dan Y (dependent). Metode yang biasa dipakai dalam penelitian seperti ini adalah regresi linier, baik sederhana maupun berganda. Namun, adakalanya regresi linier dengan metode OLS (Ordinary Least Square) yang dipakai tidak sesuai untuk digunakan. Regresi linier yang sering digunakan kadang terjadi pelanggaran asumsi Gauss-Markov. Misalnya pada kasus dimana variabel dependent (Y) bertipe data nominal, sedangkan variabel bebas/prediktornya (X) bertipe data interval atau rasio. Ingin diketahui apakah mahasiswa sudah melek keuangan berdasarkan jenis kelamin, fakultas yang dipilih dan indeks prestasi kumulatif. Dalam kasus ini hanya ada 2 kemungkinan respon mahasiswa, yaitu mahasiswa melek keuangan dan mahasiswa tidak melek keuangan.
Dari contoh kasus di atas, dapat diketahui bahwa tipe data variabel respon (Y) adalah nominal, yaitu kategorisasi keputusan mahasiswa melek keuangan atau tidak (misal melek keuangan angka 1, sedangkan tidak melek keuangan angka 0), sedangkan tipe data untuk variabel bebas (X) setidaktidaknya interval (skala likert). Bila metode regresi linier biasa diterapkan pada kasus semacam ini, menurut Kutner, dkk. (2004), akan terdapat 2 pelanggaran asumsi Gauss-Markov dan 1 buah pelanggaran terhadap batasan dari nilai duga (fitted value) dari variabel respon (Y), yaitu: 1. Error dari model regresi yang didapat tidak menyebar normal. 2. Ragam (variance) dari error tidak homogen (terjadi heteroskedastisitas pada ragam error). 3. Sedangkan, pelanggaran bagi batasan nilai duga Y (fitted value) adalah bahwa nilai duga yang dihasilkan dari model regresi linier biasa melebihi rentang antara 0 s.d. 1. Hal ini jelas tidak masuk akal , karena batasan nilai pada variabel Y (dalam kasus ini adalah Pemahaman literasi keuangan tinggi =1 dan Pemahaman literasi keuangan rendah =0). Untuk mengatasi masalah ini, diperkenalkan metode Regresi Logistik. Regresi logistik (kadang disebut model logistik atau model logit), dalam statistika digunakan untuk prediksi probabilitas kejadian suatu peristiwa dengan mencocokkan data pada fungsi logit kurva logistik. Regresi logistik adalah sebuah pendekatan untuk membuat model prediksi seperti halnya regresi linear atau yang biasa disebut dengan istilah Ordinary Least Squares (OLS) regression. Perbedaannya adalah pada regresi logistik, peneliti memprediksi variabel terikat yang berskala dikotomi. Skala dikotomi yang dimaksud adalah skala data nominal dengan dua kategori, misalnya: Ya dan Tidak, Baik dan Buruk atau Tinggi dan Rendah. Apabila pada OLS mewajibkan syarat atau asumsi bahwa error varians (residual) terdistribusi secara normal. Sebaliknya, pada regresi logistik tidak dibutuhkan asumsi tersebut sebab pada regresi logistik mengikuti distribusi logistik
Uji Model Persamaan Regresi Logistik (skripsi dan tesis)
Uji ini sering disebut juga sebagai uji ketepatan model. Uji ini digunakan untuk mengatahui apakah model regresi logistik sudah sesuai dengan data observasi yang diperoleh. Untuk menilai ketepatan model regresi logistik dalam penelitian ini diukur dengan nilai chi square dengan uji Hosmer dan Lemeshow. Pengujian ini akan melihat nilai goodness of fit test yang diukur dengan nilai chi square pada tingkat signifikansi, dimana tingkat signifikansi pada penelitian ini adalah 5%. Uji Hosmer dan Lemeshow ini disebut juga uji t yaitu uji signifikansi konstanta dan setiap variabel independen. Kriteria Statistiknya dapat dilihat dari tabel Hosmer and Lemeshow dari hasil olah data.
Uji hipotesis: : Model sesuai (Model mampu menjelaskan data empiris) :
Model tidak sesuai (Model tidak mampu menjelaskan dataempiris)
Kriteria Pengujian: : ditolak bila probabilitas ≤ 0,05 : diterima bila probabilitas > 0,05
Analisis Regresi Logistik (skripsi dan tesis)
Model regresi merupakan komponen penting dalam beberapa analisis data dengan menggambarkan hubungan antara variabel respon dan satu atau beberapa variabel penjelas. Pada umumnya analisis regresi digunakan untuk menganalisis data dengan variabel respon berupa data kuantitatif. Akan tetapi sering juga ditemui kasus dengan variabel responnya bersifat kualitatif/kategori. Untuk mengatasi masalah tersebut maka dapat digunakan model regresi logistik. Pendekatan model persamaan regresi logistik digunakan karena dapat menjelaskan hubungan antara variabel bebas dan peluangnya yang bersifat tidak linear, ketidaknormalan sebaran dari variabel terikat, serta keragaman respon yang tidak konstan dan tidak dapat dijelaskan oleh model regresi linear biasa (Agresti, 1990). Menurut Hosmer (1989), metode regresi logistik adalah suatu metode analisis statistika yang mendeskripsikan hubungan antara peubah respon yang memiliki dua kategori atau lebih dengan satu atau lebih peubah penjelas berskala kategori atau interval. Yang dimaksud dengan peubah kategorik yaitu peubah yang berupa data nominal dan ordinal. Pada dasarnya regresi logistik sama dengan analisis diskriminan, perbedaan ada pada jenis data dari variabel dependen. Jika pada analisis diskriminan variabel dependen adalah data rasio, maka pada regresi logistik variabel dependen adalah data nominal. Data nominal di sini lebih khusus adalah data binary. Dengan demikian, tujuan regresi logistik adalah pembuatan sebuah model regresi untuk memprediksi besar variabel dependen yang berupa variabel binary dengan menggunakan data variabel independen yang sudah diketahaui besarnya. Regresi logistik biner adalah salah satu metode statistika yang sering digunakan untuk mengklasifikasikan sejumlah pengamatan dengan respon biner ke dalam beberapa kelompok berdasarkan satu atau lebih variabel prediktor. Melalui metode ini akan dihasilkan peluang dari masing-masing kategori respon yang akan dijadikan sebagai pedoman pengklasifikasian dan suatu pengamatan akan masuk kedalam respon kategori tertentu berdasarkan nilai peluang yang terbesar. Pada Regresi logistik biner (dikotomus), variabel responnya mempunyai dua kategori. Fenomena dimana variabel responnya dua (bivariat) dan masingmasing berkategorikan biner, dapat dianalisis mengunakan regresi logistik biner bivariat, dengan asumsi antar peubah respon biner terdapat dependensi.
Regresi logistik cukup baik dan sering digunakan. Regresi logistik memiliki beberapa keuntungan dibandingkan regresi lainnya, yaitu: 1. Regresi logistik tidak memiliki asumsi normalitas atas variabel bebas yang digunakan dalam model. Artinya variabel penjelas tidak harus memiliki distribusi normal, linier, maupun memiliki varian yang sama dalam setiap group. 2. Variabel dalam regresi logistik dapat berupa campuran dari variabel kontinu, diskrit, dan dikotomis. 3. Regresi logistik amat bermanfaat digunakan apabila distribusi respon atas variabel terikat diharapkan non linier dengan satu atau lebih variabel bebas